





























































































































































































Kubernetes 常见故障深度解析
2025/08/19
作者:博睿谷Eva
")
Kubernetes(简称 k8s)作为容器编排领域的事实标准,其分布式架构与组件协同特性决定了故障发生的复杂性。从控制平面组件异常到节点通信中断,从 Pod 调度失败到存储挂载超时,任何环节的微小偏差都可能引发集群级故障。本文基于生产环境实践,系统梳理 k8s 核心组件的典型故障模式,提供可落地的诊断思路与修复方案,帮助运维人员建立故障处理的系统化思维。
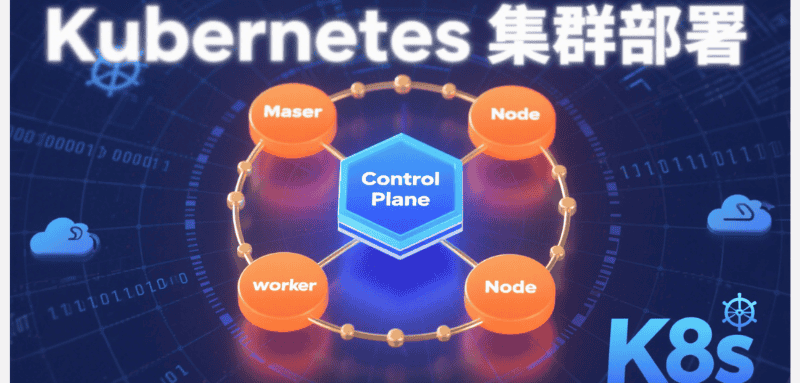
一、控制平面故障:集群大脑的异常排查
控制平面作为 k8s 集群的决策核心,由 API Server、etcd、Scheduler、Controller Manager 等组件构成,其稳定性直接决定集群可用性。
API Server 连接超时
表现特征:kubectl命令持续返回Unable to connect to the server: dial tcp
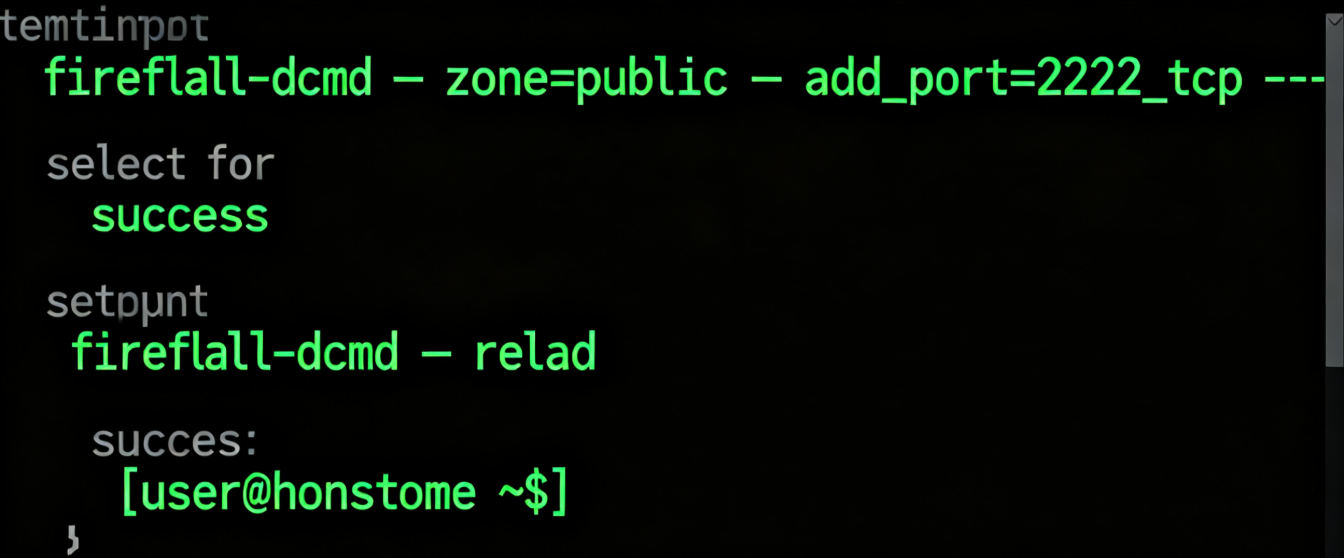
底层原因通常有三类:一是 API Server 进程未启动(查看kube-apiserver容器状态:crictl ps | grep kube-apiserver);二是 6443 端口被防火墙拦截(检查节点iptables -L | grep 6443或firewalld-cmd --list-ports);三是 etcd 集群不可用导致 API Server 启动失败(查看日志关键词:failed to connect to etcd: context deadline exceeded)。
修复步骤:首先通过journalctl -u kubelet -f查看 kubelet 日志,确认 API Server 容器是否正常运行。若容器反复重启,需检查挂载的证书文件(通常位于/etc/kubernetes/pki)是否过期 —— 可通过openssl x509 -in apiserver.crt -noout -dates验证有效期,过期则需使用kubeadm certs renew重新生成。若证书正常,进一步检查 etcd 集群健康状态:etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/apiserver-etcd-client.crt --key=/etc/kubernetes/pki/apiserver-etcd-client.key endpoint health,etcd 节点异常需优先修复。
etcd 数据损坏或集群分裂
表现特征:API Server 能启动但响应缓慢,部分资源操作返回500 Internal Server Error,etcd 日志出现mvcc: database space exceeded或raft: failed to commit log。
当 etcd 数据目录磁盘空间不足(默认超过 90% 会触发只读保护),需执行碎片整理:etcdctl defrag --endpoints=https://127.0.0.1:2379 ...,并清理过期事件(kubectl delete events --all-namespaces --field-selector type!=Normal)。若发生集群分裂(多数节点失联),需先确认健康节点,通过etcdctl member list移除故障成员,再添加新节点重建集群 —— 注意使用--initial-cluster-state existing参数避免数据覆盖。
Scheduler 调度异常
表现特征:Pod 长时间处于Pending状态,事件显示0/3 nodes are available: 3 node(s) didn't match node selector,但实际节点标签符合选择器规则。
排查重点:kube-scheduler日志中是否存在failed to schedule pod错误,常见原因包括:节点亲和性规则冲突(检查nodeAffinity配置)、资源请求超过节点可分配量(kubectl describe node
二、节点故障:工作负载的载体异常
节点作为 Pod 运行的物理载体,其健康状态直接影响工作负载稳定性,常见故障集中在 kubelet 通信、容器运行时与资源耗尽三个维度。
kubelet 未就绪(NotReady)
表现特征:kubectl get nodes显示节点状态为 NotReady,Pod 无法调度至该节点,已运行 Pod 可能被驱逐。
诊断流程:登录节点执行systemctl status kubelet,若服务未启动,检查配置文件/etc/kubernetes/kubelet.conf是否存在语法错误;若服务运行但状态异常,查看日志journalctl -u kubelet -f | grep -i error,典型错误包括:
container runtime is not running:容器运行时(containerd/cri-o)未启动,执行systemctl start containerd并设置开机自启
failed to pull image "k8s.gcr.io/pause:3.6":pause 镜像拉取失败,配置镜像仓库镜像(如ctr images pull registry.aliyuncs.com/google_containers/pause:3.6)后重新打标签
node "node-1" not found:kubelet 证书与 API Server 认证失败,删除/etc/kubernetes/kubelet.conf后通过kubeadm reset重置节点再重新加入集群
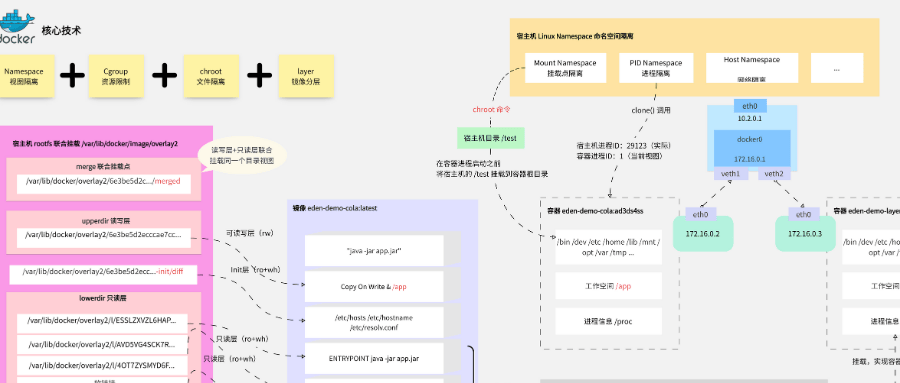
容器运行时异常
表现特征:crictl ps命令无响应,容器启动失败,日志显示context deadline exceeded。
containerd 常见故障修复:检查/run/containerd/containerd.sock是否存在,若缺失则重启服务;若出现镜像层损坏(failed to mount overlay),清理损坏镜像ctr images rm
节点资源耗尽
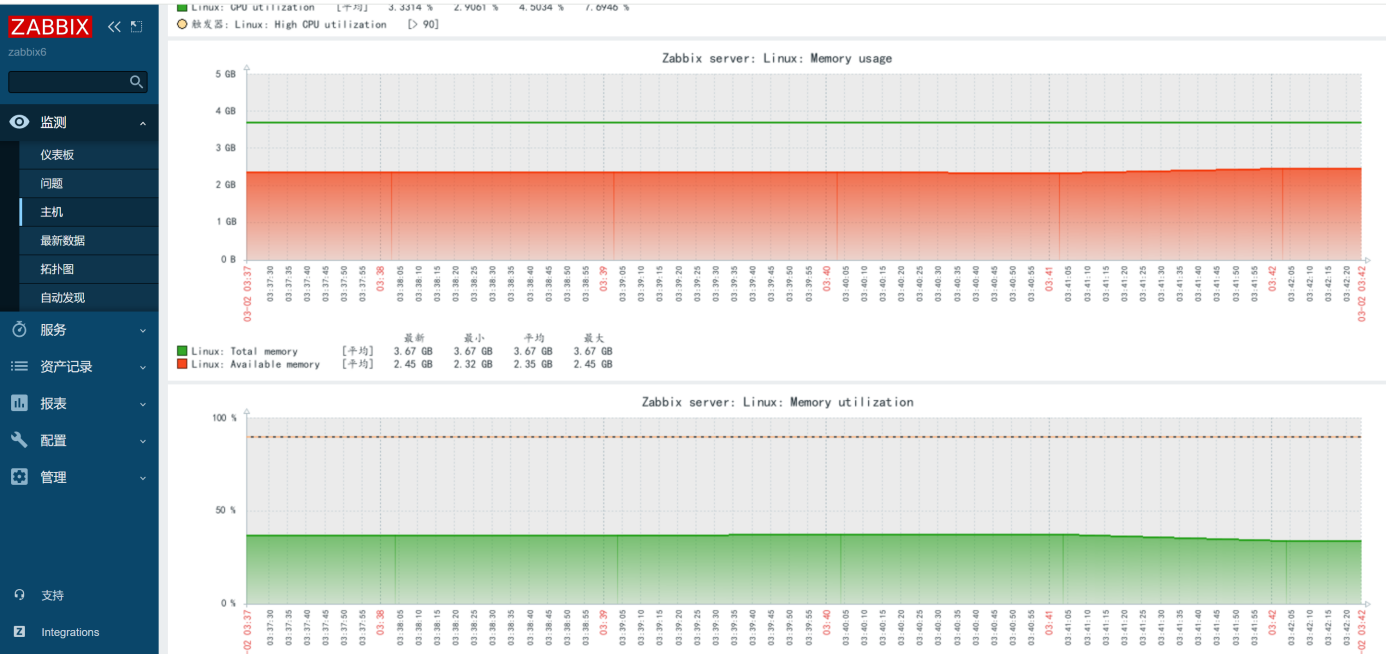
表现特征:节点上 Pod 频繁被杀死(OOMKilled),dmesg日志出现Out of memory: Killed process,kubectl top node显示内存使用率超过 90%。
临时缓解措施:识别并删除资源消耗异常的 Pod(kubectl top pod -n
三、Pod 故障:工作负载的实例异常
Pod 作为 k8s 最小部署单元,其故障表现形式多样,需结合生命周期、容器状态与调度规则综合分析。
Pod 调度失败(Pending)
除前文提到的节点选择器问题外,常见原因还包括:
资源不足:节点可分配 CPU / 内存无法满足 Pod 请求,通过kubectl describe pod
-n 查看Events字段,确认是否存在Insufficient cpu或Insufficient memory,调整resources.requests至合理范围
节点污点与 Pod 容忍不匹配:节点存在NoSchedule污点(kubectl describe node
| grep Taint),需在 Pod.spec 中添加对应tolerations配置
PVC 绑定失败:PersistentVolumeClaim is not bound,检查 PV 是否存在且与 PVC 的storageClassName、accessModes匹配,必要时手动创建 PV
容器启动失败(CrashLoopBackOff)
表现特征:Pod 状态频繁在Running与CrashLoopBackOff间切换,kubectl logs
典型修复场景:
入口命令错误:容器command或args配置有误,导致进程启动后立即退出,可通过kubectl exec -it
-n -- sh进入容器验证命令可行性
健康检查失败:livenessProbe配置过于严格(如initialDelaySeconds过短),导致应用未就绪即被杀死,延长初始化等待时间或调整检查阈值
权限问题:容器内进程尝试访问受限资源(如宿主机文件),需在securityContext中设置privileged: true或添加capabilities
Pod 网络不通
表现特征:Pod 间无法通信,kubectl exec进入容器后ping其他 Pod IP 超时,服务发现失败。
排查步骤:
检查 CNI 插件状态(如 Calico:kubectl get pods -n calico-system),异常则重启相关 Pod
验证 Pod IP 分配:kubectl get pod
-o wide确认 IP 在集群 CIDR 范围内
检查节点间网络策略:是否存在 NetworkPolicy 阻止 Pod 通信,临时添加allow-all策略测试
对于 Calico 网络,执行calicoctl node status查看 BGP 连接状态,异常节点需检查防火墙规则(允许 179 端口)
四、存储故障:数据持久化的稳定性挑战
存储故障往往涉及 PV/PVC 绑定、挂载操作与后端存储服务,排查需跨越 k8s 层与基础设施层。
PVC 一直处于 Pending 状态
核心原因是没有匹配的 PV 可用,需从三方面检查:
存储类匹配:PVC 指定的storageClassName是否存在(kubectl get sc),若使用默认存储类,确认其provisioner配置正确
资源需求匹配:PVC 的storage请求是否超过所有可用 PV 的容量,或accessModes(如ReadWriteOnce)与 PV 不兼容
卷绑定模式:若存储类使用WaitForFirstConsumer绑定模式,需等待首个 Pod 使用 PVC 后才会自动创建 PV,可临时切换为Immediate模式测试
Pod 挂载 PVC 失败(Error)
表现特征:Pod 状态为Error,事件显示FailedMount: MountVolume.SetUp failed。
常见场景修复:
NFS 挂载失败:检查nfs-server是否可达,Pod 所在节点是否安装nfs-utils,导出目录权限是否为777
CSI 插件问题:查看 CSI 控制器 Pod 日志(如kubectl logs -n kube-system csi-attacher-xxx),确认是否存在volume not found错误,重启 CSI 组件
权限不足:PV 的persistentVolumeReclaimPolicy设置为Retain时,手动清理旧数据目录后重新绑定
存储后端故障
当 PV 对应的后端存储(如 Ceph、GlusterFS)出现问题,会导致 Pod 读写数据超时,表现为IOError: [Errno 121] Remote I/O error。此时需优先排查存储集群健康状态:检查 OSD 是否在线(Ceph)、Gluster 卷是否正常(gluster volume status),待存储服务恢复后,执行kubectl delete pod
五、故障预防体系:构建主动防御机制
解决故障的最佳方式是预防,建议建立多层次防御体系:
监控告警:部署 Prometheus 监控核心指标(如 API Server 响应时间、节点资源使用率、Pod 重启次数),设置阈值告警(如节点 NotReady 持续 5 分钟)
健康检查:为所有工作负载配置livenessProbe与readinessProbe,结合startupProbe处理慢启动应用
自动恢复:利用 k8s 自愈能力,对 Deployment 设置合理的replicas,配合 PodDisruptionBudget 保证最小可用实例
备份策略:定期备份 etcd 数据(etcdctl snapshot save),关键应用数据通过 CSI 快照功能保护
混沌工程:定期进行故障注入测试(如关闭一个 etcd 节点、模拟网络延迟),验证集群容错能力
Kubernetes 故障处理的核心原则是 "分层排查、由表及里"—— 从 Pod 状态到节点状态,再到控制平面组件,逐步缩小范围。建立完善的日志收集体系(如 ELK Stack)和监控看板,能大幅缩短故障定位时间。同时,深入理解各组件的工作原理,而非仅依赖经验主义,才能应对复杂场景下的故障挑战。随着集群规模扩大,引入 GitOps 工具(如 Flux、Argo CD)实现配置即代码,可从源头减少人为操作引发的故障,这也是现代化 k8s 运维的必然趋势。
-
开设课程 开班时间 在线报名OCP2025.04.26
在线报名
HCIP-AI Solution2025.04.26在线报名
HCIE-openEuler2025.05.03在线报名
RHCA-CL2602025.05.04在线报名
HCIP-Cloud2025.05.10在线报名
PGCM直通车2025.05.10在线报名
HCIA-Datacom(晚班)2025.05.19在线报名
HCIA-Sec2025.06.07在线报名
RHCA-RH4422025.06.07在线报名
PMP2025.06.10在线报名
HCIA-Datacom2025.06.14在线报名
HCIE-AI Solution2025.06.14在线报名
HCIE-Datacom2025.06.14在线报名
HCIP-Datacom(晚班)2025.06.16在线报名
OCM2025.06.21在线报名
HCIE-Cloud2025.06.21在线报名
HCIP-Sec2025.06.21在线报名
HCIE-Bigdata2025.06.28在线报名
RHCE2025.06.28在线报名
HCIE-Datacom考前辅导2025.07.05在线报名
HCIP-Datacom深圳2025.07.19在线报名
CISP2025.07.19在线报名
HCIA-Datacom(晚班)2025.07.21在线报名
RHCA-RH4362025.07.26在线报名
OCP2025.07.26在线报名
HCIE-Sec2025.08.09在线报名
HCIA-AI Solution2025.08.16在线报名
HCIP-Datacom(晚班)2025.08.25在线报名
RHCA-RH3582025.09.06在线报名
PMP2025.09.16在线报名
HCIE-Datacom2025.09.06在线报名
HCIA-AI Solution2025.09.27在线报名
HCIA-Datacom2025.09.27在线报名
PGCM直通车2025.10.11在线报名
RHCA-DO3742025.10.11在线报名
HCIA-Sec2025.10.11在线报名
RHCE2025.10.18在线报名
HCIP-Datacom2025.11.08在线报名
HCIP-Sec2025.11.08在线报名
RHCA-CL2602025.11.15在线报名
OCP2025.11.15在线报名
HCIE-Sec2025.12.13在线报名
HCIE-Datacom2026.01.10在线报名