


































































































































































































Wi-Fi信号满格却频繁掉线?问题出在哪?
2025/12/30
VLAN间通信失败?三层交换机与Trunk链路核心排错指南
2025/12/26
网络卡顿 / 断网?ping/traceroute/Wireshark 排错技能汇总
2025/12/23
电脑卡顿 / 蓝屏 / 断网?CMD 命令如何一键排查?
2025/12/19
SSH 密钥泄露导致账号被盗,该如何快速补救?
2025/12/17
Linux服务器SSH连接失败怎么办?如何稳定远程登录?
2025/12/15
用户留存上不去?Python 怎么分析行为触点?
2025/12/10
K8s部署云原生应用启动慢?有哪些落地解决办法?
2025/12/08
企业客服想升级智能版?从环境配置到部署,AI 实战方案有哪些?
2025/12/05
数据重复录入太耗时?JS脚本能不能自动处理?
2025/12/03
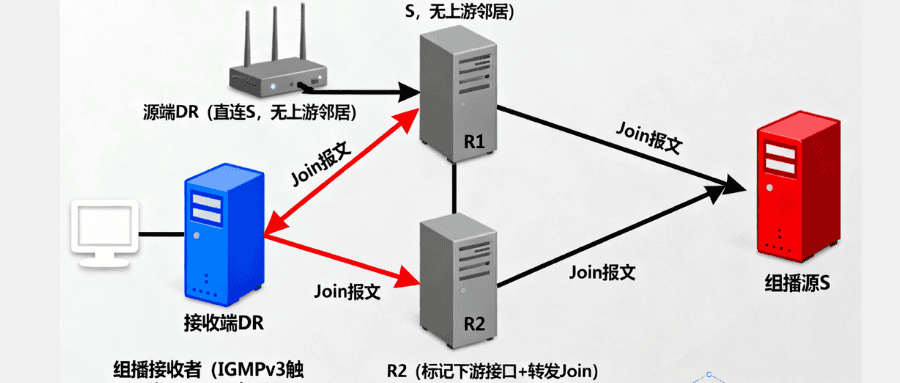
组播 SPT 树怎么构建?PIM-SM SSM 模式三步实现流程
2025/11/28
Python Web开发能做企业网站吗?入门先掌握哪些技术?
2025/11/25
Python 能自动爬网页数据吗?爬虫入门怎么做?
2025/11/18
K8s集群防护总失效?云防火墙怎么适配容器环境?
2025/11/14
WPS VBA 宏批量处理时失效?什么原因?如何稳定运行?
2025/11/11
容器崩了该找 Docker 还是 K8s?故障恢复时,两者分工差在哪?
2025/11/07
Linux 系统没备份误删文件能恢复吗?怎么做?
2025/11/03
Docker 安全漏洞太多?这张攻击树帮你理清所有风险点
2025/10/29
Linux 服务器磁盘满了?怎么快速查看文件系统的空间占用情况?
2025/10/28
用 VS Code 写 C 语言作业,环境搭了一下午还不行?学生党该怎么办?
2025/10/27
华为 eNSP 最新版本是什么?传统版与 eNSP Lite 区别在哪?
2025/10/23
用VMware隔离办公与开发?职场新人这样搭环境,文件不混、电脑不卡
2025/10/21
银河麒麟 V10 遇到故障咋解决?常见故障解决方法有什么?
2025/10/20
K8s 集群总搭失败?多节点报错有解吗?附命令!
2025/10/17
客服响应慢还易错?看AI 智能客服工作流如何拆解
2025/10/16
WPS VBA 宏突然不能用?2025 最新修复指南 + 避坑技巧
2025/10/16
与传统模拟器对比,华为新版 ENSP_Pro 究竟强在哪?
2025/10/14
Vue2 与 Vue3 核心差异在哪?
2025/10/13
想保障家庭与小型企业网络安全?知道该怎么设置吗?
2025/10/10
Excel VBA 常见报错:‘运行时错误’怎么排查?
2025/10/09
两台服务器负载均衡搭建指南 —— 掌握避坑与优化技巧
2025/10/08
IPv4v6 是什么?为何会没有网络权限?一文解答!
2025/10/08
Ansible 部署红帽 Ceph 存储:从环境到扩容一步通
2025/10/08
Oracle 索引怎么用?原理、分类及维护技巧
2025/10/07
TCP 三次握手如何成为网络通信的 “加密密钥”?一文带你探究!
2025/10/07
为何电脑能实现 IP 自动分配?原理、流程全解读
2025/09/30
MAC 地址异常怎么解决?常见报错场景 + 处理方法
2025/09/29
交换机端口配置不知如何下手?这 12 条常用操作命令你掌握了吗?
2025/09/28
机房温湿度失控会引发哪些问题?关键的注意要点你清楚吗?
2025/09/28
SSH 服务进阶配置:安全加固 + 访问控制 + 性能优化
2025/09/27
掌握 OSPF 部署与排错?OSPF 多区域实验核心内容必看!
2025/09/27
kubectl 怎么配置?附自动补全设置与基础命令
2025/09/27
在 Windows 10 上测试 UDP 端口,你知道最简单的方法是什么吗?
2025/09/26
OpenStack 和其他云平台软件相比,有啥不同?
2025/09/25
数据库性能调优怎么搞?瓶颈定位、优化方法及工具推荐
2025/09/25
2025 年 K8s 集群搭建工具大盘点:特性、优势与应用场景如何匹配?
2025/09/23
Linux Web 服务器入侵排查怎么做?四层溯源步骤及工具推荐
2025/09/23
交换基础里的 VLAN、TRUNK、VLAN 间路由该怎么学?一篇文章讲明白
2025/09/22
想让运维效率翻倍?看 K8s 如何在运维中巧妙应用
2025/09/19
项目部署效率上不去?掌握 Docker 的作用是关键!
2025/09/18
企业网络出问题?快来看看防火墙 Local/Trust 等区域策略的配置与排查
2025/09/17
华为 ENSP 怎么配置 SSH?USG6000V 实操步骤有吗
2025/09/17
CC 攻击怎么防御?技术原理及服务器影响有哪些
2025/09/16
Linux 系统下如何借助命令行工具玩转 Python 程序之编辑、存储与执行
2025/09/15
VPN 加密隧道是什么?3 种类型对比 + 网速影响 / 安全疑问解答
2025/09/15
华为 S 系列交换机默认密码多少?密码遗忘怎么恢复?
2025/09/15
VMware 虚拟机使用教程 ,软件开发与测试更顺畅的实操攻略
2025/09/12
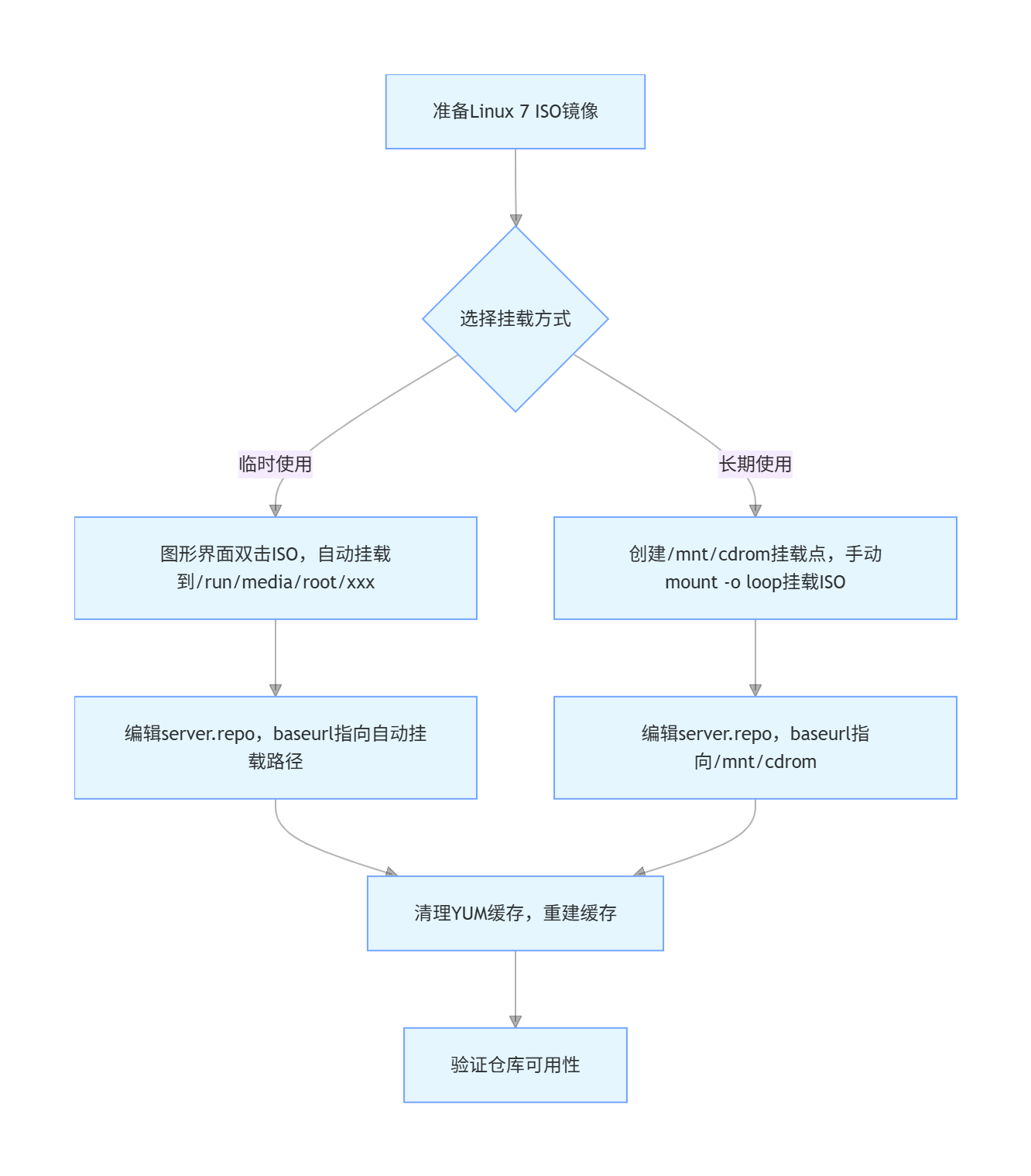
Linux 7/8 本地 YUM 仓库配置教程:从 ISO 镜像到无网环境软件管理
2025/09/11
抓包工具选 Wireshark 还是 tcpdump?怎么用能定位网络问题
2025/09/09
虚拟化技术怎么选?VMware 和 Docker 有什么区别?
2025/09/09
VMware vSphere 8.0 VCSA 怎么搭建?常见问题有哪些
2025/09/08
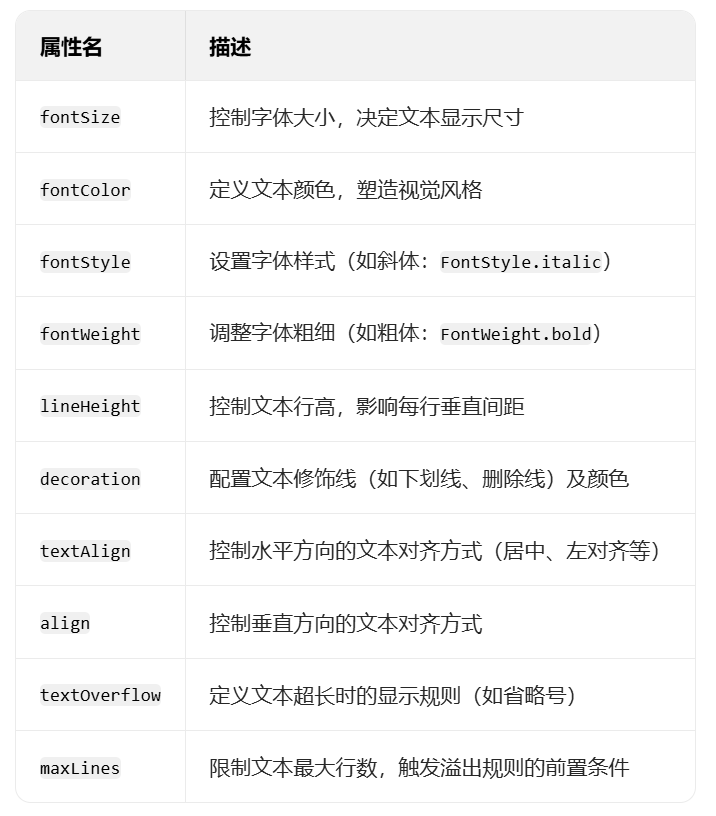
Flutter Text 组件怎么用?核心属性有哪些?
2025/09/03
防火墙 IPSec 报文怎么统计?华为华三配置有啥不同?
2025/09/01
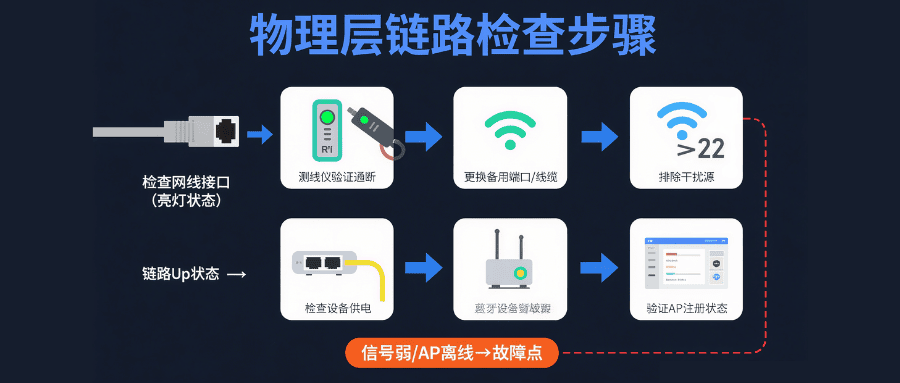
网络ping不通?物理链路检查从哪入手?
2025/08/28
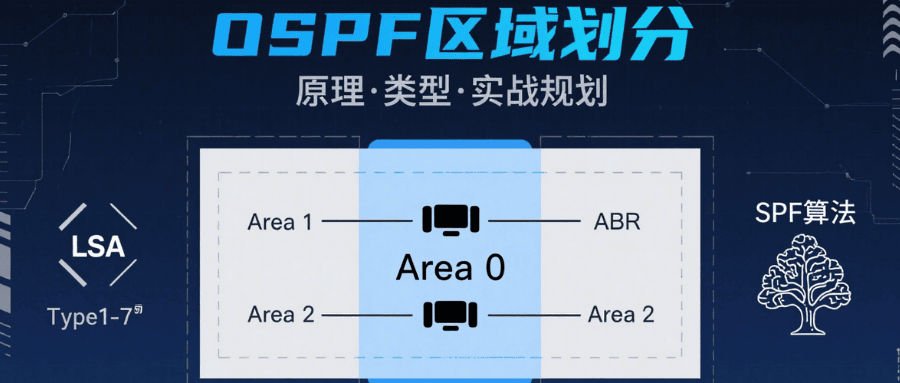
OSPF 区域划分怎么操作?核心原则是什么
2025/08/28
OSPF 邻居建立失败怎么解决?10 大影响因素有哪些?
2025/08/27
渗透测试各阶段用什么工具?信息收集到报告生成工具清单
2025/08/26
DevEco Studio 常用快捷键:HarmonyOS 鸿蒙开发效率提升指南
2025/08/21
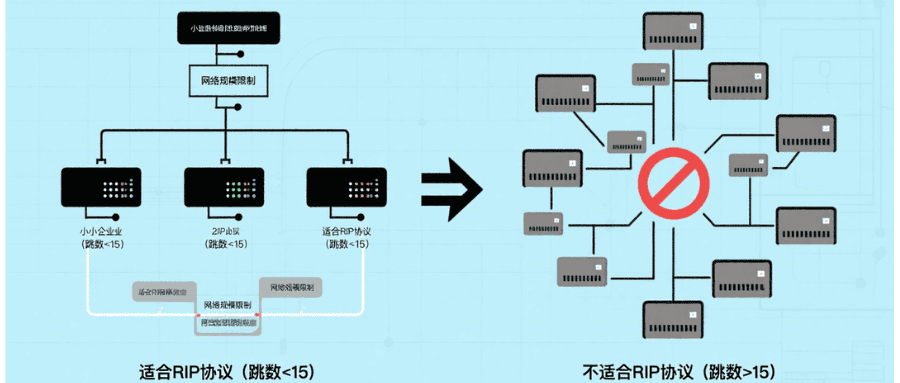
RIP协议详解:距离矢量路由协议的工作机制与应用
2025/08/20
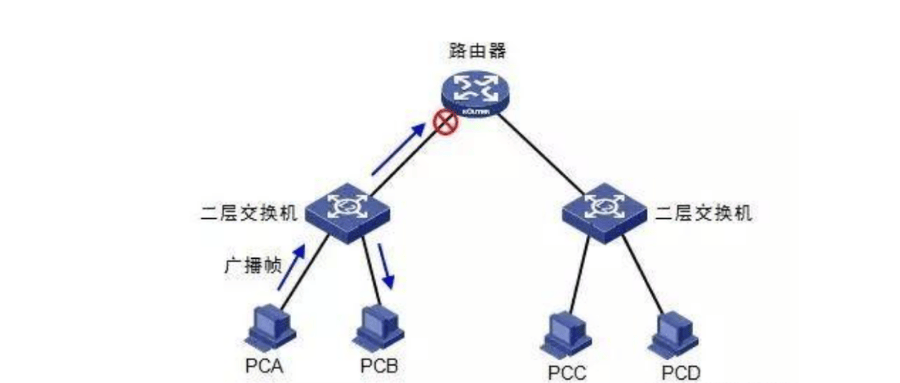
交换机工作原理是什么?
2025/08/20
Kubernetes 常见故障深度解析
2025/08/19
Python 爬虫核心库全解析:从请求到解析的完整技术图谱
2025/08/19
OpenEuler 支持的主流编程语言盘点
2025/08/18
osi七层模型和tcp/ip模型的区别
2025/08/14
防火墙故障排查手册:常见难题一网打尽?
2025/08/08
50 个高危及常用网络端口全解析:风险原理与防护策略大全
2025/08/08
20 大核心网络协议详解:从 TCP/IP 到 OSPF,原理 + 实战场景全解析
2025/08/07
IP 地址与子网掩码详解:组成、作用及协同工作原理
2025/08/07
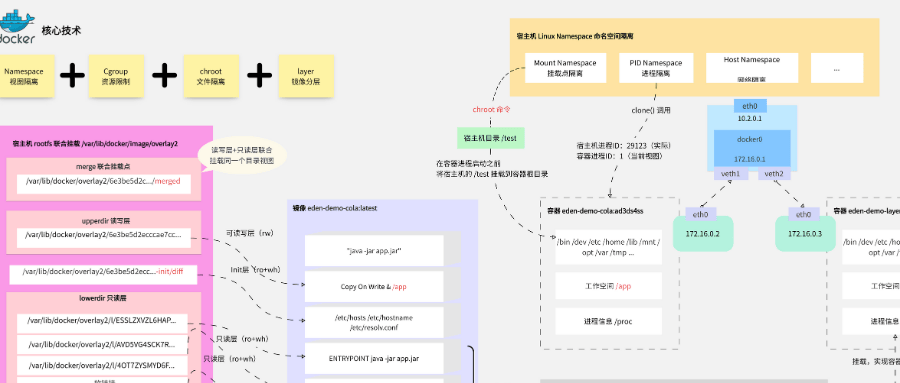
Docker 核心技术深度剖析:从 Namespace 到容器运行时原理详解
2025/07/31
安装部署 Kubernetes(k8s)
2025/07/30
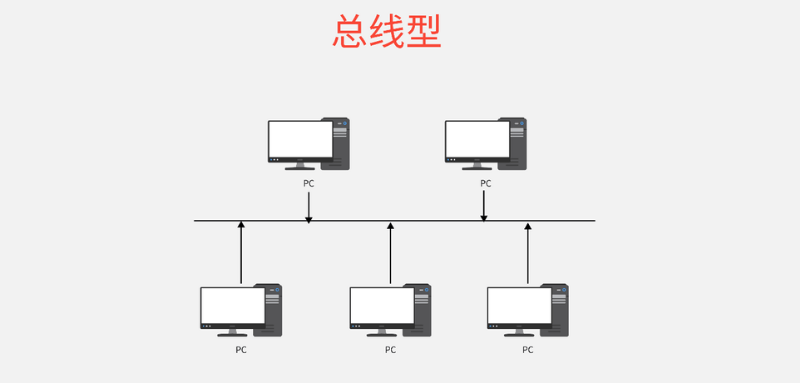
常见网络拓扑结构有哪些?网络工程师必看内容
2025/07/30
OSPF 常见错误分析及排查思路
2025/07/21
eNSP 安装后如何快速完成设置?
2025/07/15
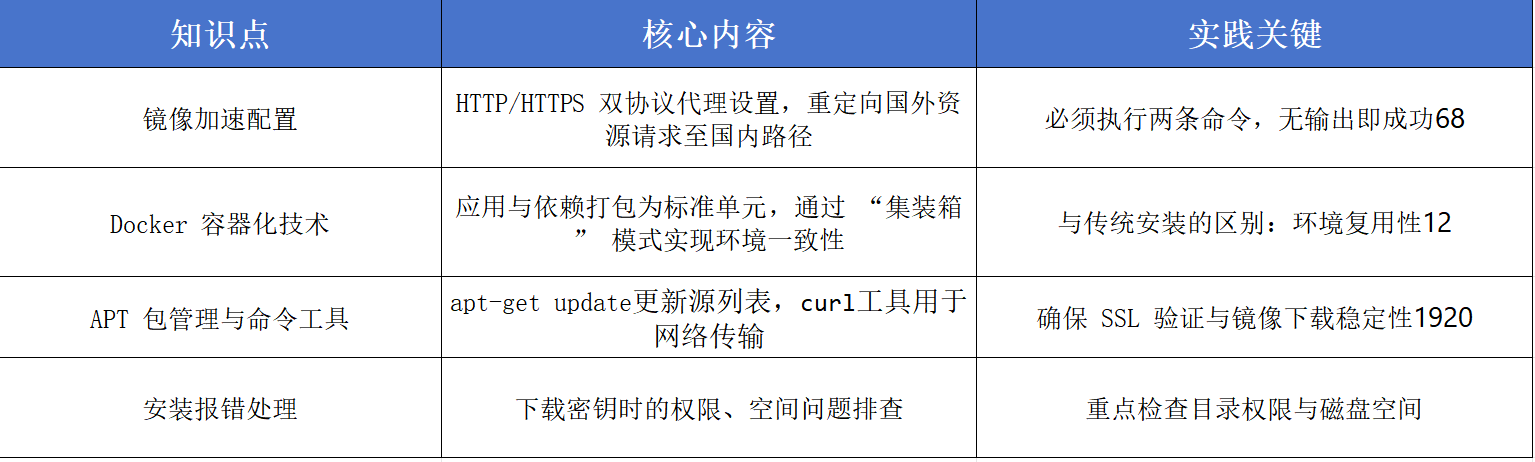
Docker 部署实战:国内镜像加速与容器化
2025/07/14
网络安全学习资源之靶机实验平台
2025/07/11
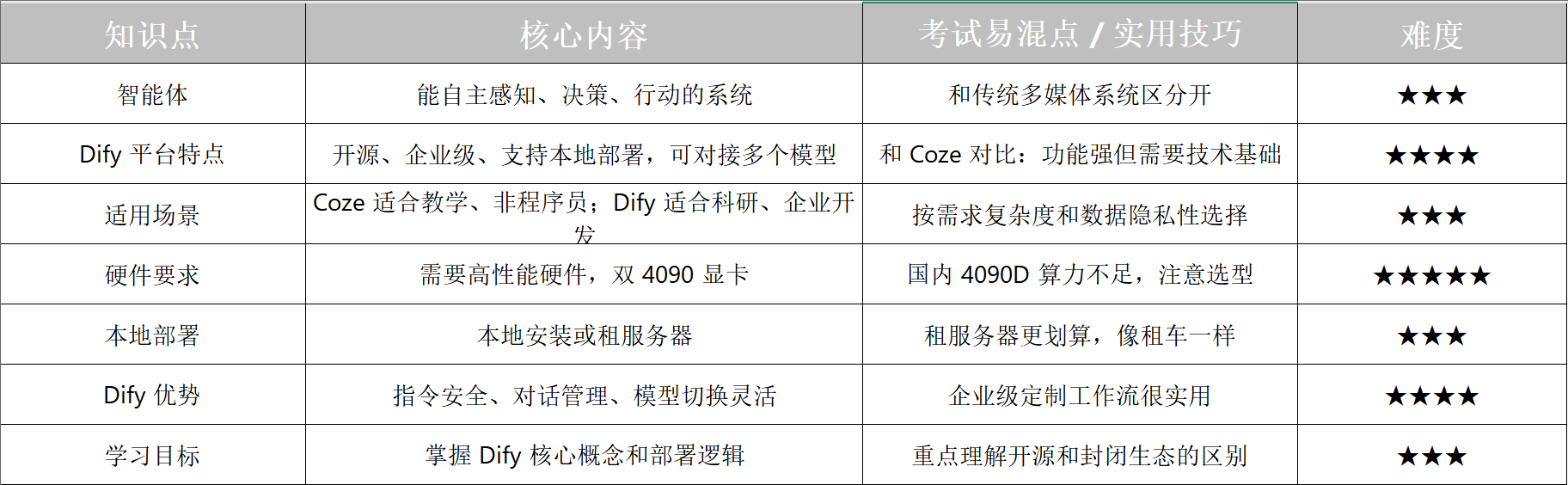
人工智能大模型怎么用?智能体与 Dify 平台超详细科普
2025/07/08
想在 Linux 环境部署 Oracle 19C?这份指南请收好
2025/07/03
如何高效部署华为 OpenStack 环境?快速上手教程
2025/07/01
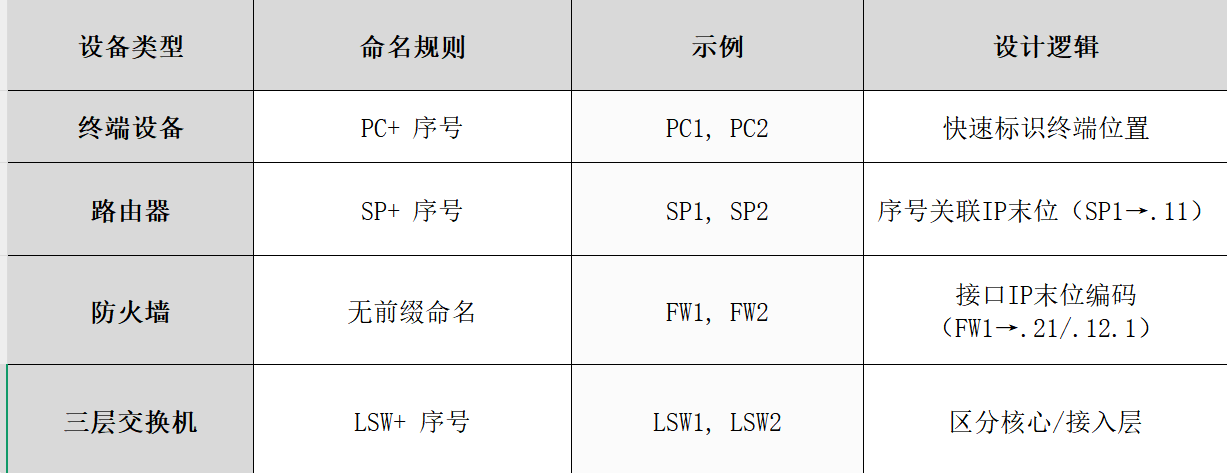
华为网络拓扑命名规则详解:设备编号、IP规划、接口配置
2025/06/23
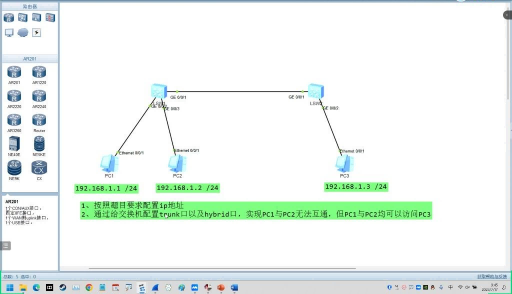
Hybrid 接口实验全流程解析:从 VLAN 规划到连通性测试
2025/06/20
华为 eNSP 和 Virtualbox 重装流程是什么?必会步骤详解
2025/06/19
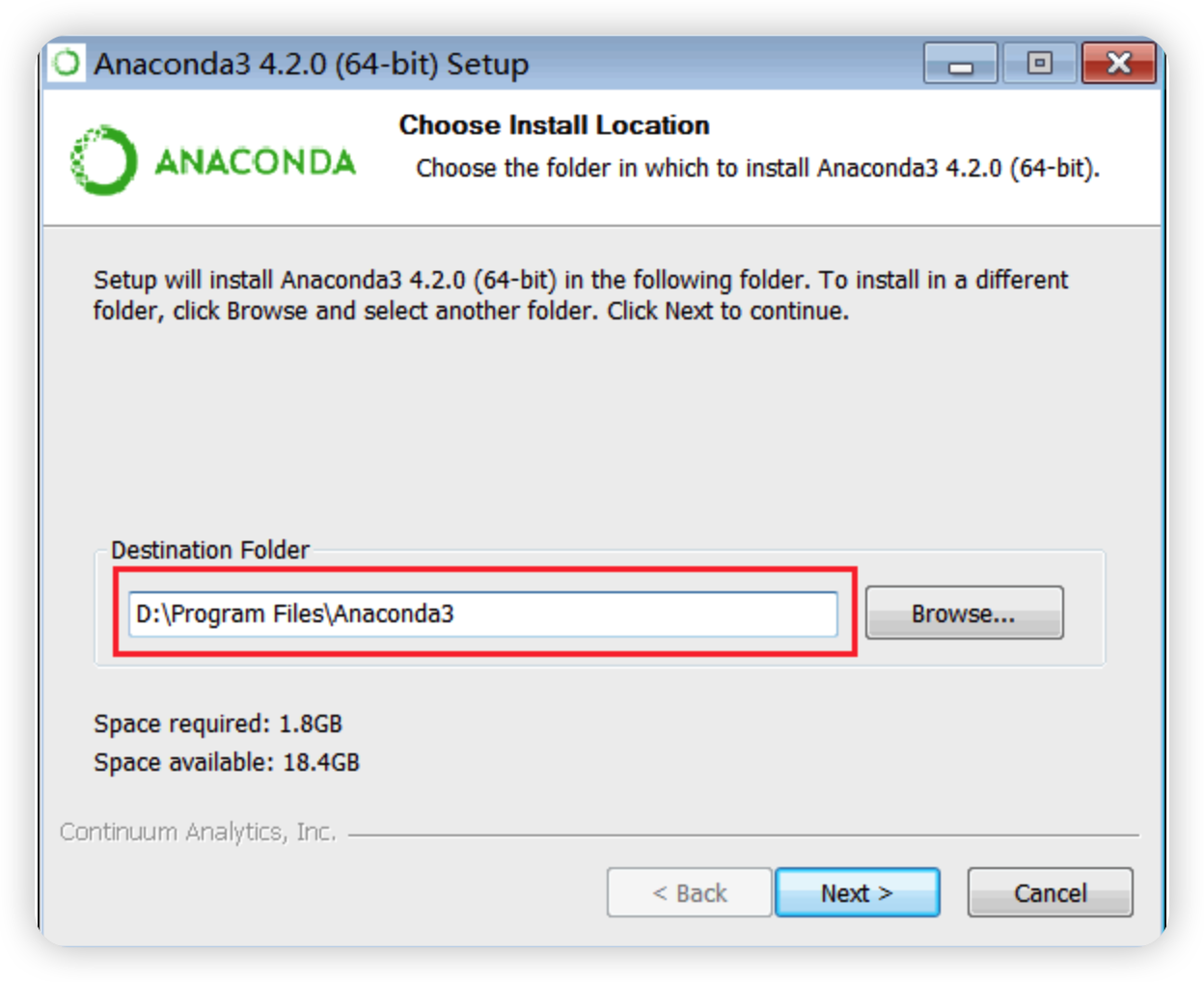
如何在Windows上用Anaconda搭建Python开发环境?
2025/06/10
如何高效创建虚拟机?VMware Workstation Pro详细步骤解析
2025/06/09
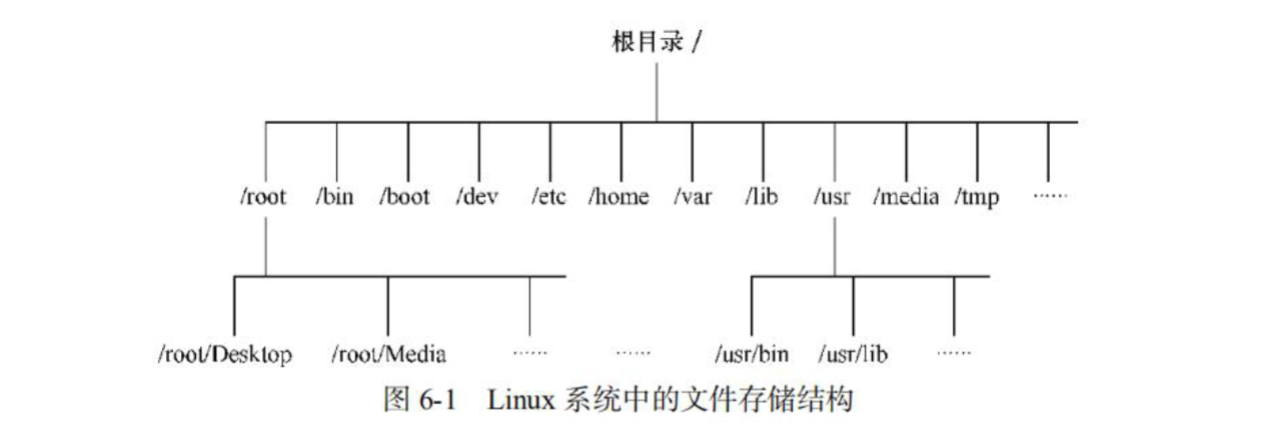
Linux文件系统核心目录结构与FHS标准
2025/06/03
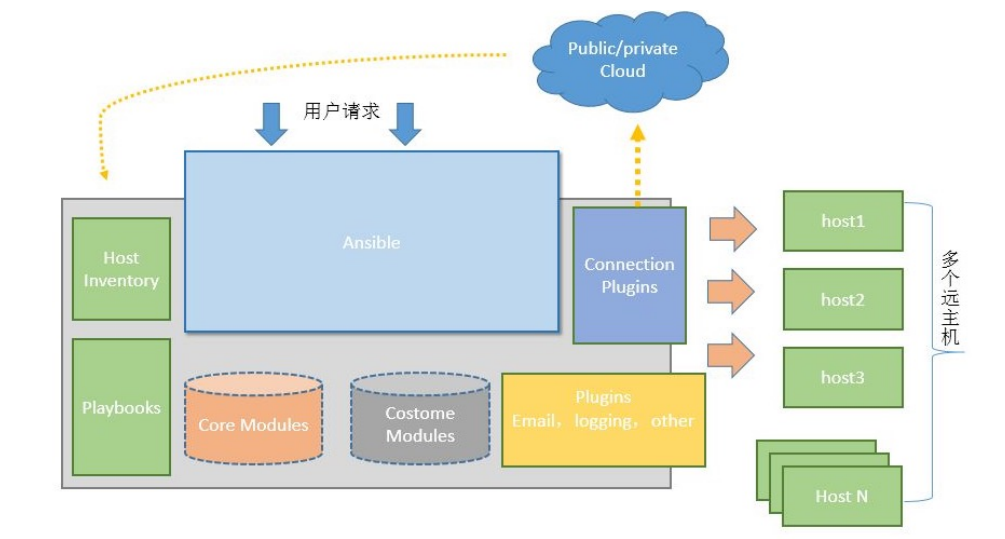
Ansible的原理与安装
2025/05/29
访问网络交换机的Access、Trunk、Hybrid模式如何选?
2025/05/26
Oracle数据库复杂查询性能优化指南:系统化排查与调优策略
2025/05/21
VLAN配置与排错6步法
2025/05/15
Web开发工具清单及推荐
2025/05/08
直连设备Ping不通如何排查与解决?
2025/05/07
OpenStack与红帽Ceph集成及CL261考试解析
2025/05/07
MAC地址、物理地址与链路层地址:概念辨析与技术实现
2025/05/06
如何选Linux认证?零基础怎么选?
2025/04/30
如何部署SSL证书,实现https访问呢?
2025/04/28
云服务是什么?一文读懂云计算的核心概念、服务模式与行业应用
2025/04/27
RHCSA必会命令速查表:哪些命令是考试关键?
2025/04/27
运维工程师的证书选哪个靠谱?
2025/04/27
HTTP和HTTPS的区别在哪?
2025/04/25
HCIP安全认证:实验题实战要点
2025/04/24
为什么选择PostgreSQL而非MySQL?
2025/04/24
云原生时代Docker会被淘汰?K8s集群管理与容器化实战如何选择
2025/04/15
路由交换技术问题怎么解决?VLAN通信、OSPF邻居、ACL配置常见故障Q&A
2025/04/14
Kubernetes进阶知识深度解析:从控制器到生态集成
2025/04/11
HCIP和HCIE实验题难度差距有多大?
2025/04/10
Kubernetes架构与实践指南
2025/04/10
错误代码定位故障的工程化方法
2025/04/10
路由与交换技术精要指南:从网络架构到高阶运维的实战方法论
2025/04/09
RHCE考试实战技巧:高效通关的12个关键策略
2025/04/09
红帽RHCE认证考前辅导环境详解_博睿谷在线教育
2025/04/09
vSphere环境搭建步骤:ESXi 7.0和vCenter 8.0安装配置
2025/03/31
ITIL认证培训课程_零基础快速掌握IT服务管理
2025/03/31
想考网络工程师班?需要具备哪些条件?
2025/03/23
华为云计算认证HCIA,HCIP,HCIE都涵盖哪些学习内容?
2025/03/23
基于DeepSeek的网络安全自动化解决方案:漏洞挖掘与攻防效率提升
2025/03/20
网络工程师路由交换代码手册:Cisco/华为命令对照表+OSPF调优参数
2025/03/19
红帽OpenStack部署(基于RHOSP 17/18版本)
2025/03/18
Python自动化代码库:Excel/爬虫/邮件告警场景模板即用
2025/03/17
ENSP必会命令全集:VLAN/OSPF/ACL配置+排错指令
2025/03/17
Oracle与国产数据库替代成本对比表
2025/03/16
Linux 工具包:系统管理、开发与运维全场景工具指南
2025/03/16
华为欧拉HCIA认证值得考吗?关键因素分析与决策建议
2025/03/13
网络工程师培训你了解多少?
2025/03/13
CKA认证是什么?考试全攻略:核心考点+高效备考+真题解析
2025/03/13
Linux安装部署PostgreSQL详细步骤
2025/03/13
PostgreSQL高可用性配置有哪些最佳实践?
2025/03/12
openEuler企业级部署如何维护?涵盖硬件验证、集群架构及内核调优!
2025/03/11
RHCSA认证一次考过有何秘诀?要点全解析!
2025/03/10
网络工程师必备哪些知识点?从协议到云网实战全解析(附命令)!
2025/03/10
华为HCIP认证都考些什么内容?
2025/03/09
页面定时刷新与跳转技术:实现方案与代码实战
2025/03/06
Linux认证含金量大比拼:RHCE、LPI、Linux+,哪个才是你的职场加速器?
2025/03/06
Pearson VUE考试证件政策完全解读:避免因证件问题被拒考
2025/03/06
STP与RSTP协议对比:端口角色及端口状态解析
2025/03/03
华为认证考场应急操作手册(2024版)
2025/03/03
红帽认证通关秘籍:两大核心板块+高频考点全曝光
2025/02/28
HCIE-Datacom实验:静态路由配置详解
2025/02/24
华为eNSP模拟器深度指南:架构解析/实验配置/故障排除全攻略(含替代方案)
2025/02/23
常见网络协议汇总_入门到精通指南
2025/02/13
Oracle 19c 安装与基础配置全流程指南
2025/02/12
信创证书,2025年的热门证书介绍
2025/02/07
C语言连接MySQL数据库常见错误及解决方案
2025/02/06
HCIE认证考试最新避坑全攻略!
2025/01/20
MySQL开源数据库之一,职业发展与技术进阶指南
2025/01/11
数据库MySQL事务处理
2025/01/10
华为认证重新认证攻略
2024/12/22
红帽认证考取攻略
2024/12/11
如何快速通过Oracle OCM证书考试
2024/12/04
来自OCM学员的学习经验与教训
2024/12/02
RHCE认证考试报名指南
2024/11/29
HCIE培训班费用解析及选择指南:考生必读的四大标准
2024/11/28
如何在Linux环境下使用Python脚本有效导出Oracle数据库的方法
2024/11/25
HCIE考试怎么过?听听这位学霸怎么说!
2024/11/20
OCM考试知识点汇合以及备考攻略
2024/11/19
Oracle 19c OCP认证培训全攻略
2024/11/18
HCIA-Datacom练习题
2024/11/16
最新RHCSA题库练习_博睿谷培训订阅
2024/11/13
OCP认证培训班?博睿谷培训课程推荐
2024/11/11
Oracle数据库表查询:深入理解和高效执行
2024/11/10
华为欧拉考试大纲介绍
2024/11/06
HCIA的题型有哪些?
2024/11/04
HCIE-Datacom实验考试如何高效备考?
2024/11/02
OCM考试须知:从零开始备考攻略
2024/11/01
HCIA认证培训怎么选?博睿谷订阅培训
2024/10/27
拥有HCIE级网络工程师资格的你能拿多少工资?
2024/10/25
如何高效备考一个月拿下PMP认证考试?
2024/10/20
MySQL OCP认证和Oracle OCP认证的差异?
2024/10/18
RHCE考试心得分享:何同学经历总结,助你高分通过
2024/10/14
华为安全HCIE认证是什么?怎么考试?_博睿谷订阅培训
2024/10/12
2024年华为HCIE认证报名费用多少?报名流程分享
2024/10/11
RHCSA最新考试题库
2024/10/10
19c OCM考试时间安排与备考指南 - 让你轻松通过认证
2024/10/10
RHCE认证考试是有中文版本吗?
2024/10/08
欧拉操作系统(openEuler)是什么?博睿谷_订阅式培训
2024/10/03
华为认证 HCIE 笔试+实验考试指引,看完你就懂了!!
2024/10/03
华为认证与红帽认证哪个适合您?博睿谷_订阅培训
2024/10/01
华为认证零基础怎么选合适自己?博睿谷_订阅培训
2024/09/30
详细带你了解华为HCIA报名注册流程
2024/09/30
红帽RHCE考试内容以及考试攻略,这篇文章带你搞定
2024/09/30
华为HCIE认证方向哪个吃香?
2024/09/29
Oracle OCP认证考试流程及备考要点解析
2024/09/29
OCP认证培训要多久?大多数人都不知道
2024/09/29
华为认证最新学习模式,博睿谷9.9元解锁IT认证学习之旅!!
2024/09/23
快速取得Oracle认证(OCP)证书的攻略?
2024/09/23
2024年华为认证HCIA/HCIP/HCIE笔试实验考试预约流程攻略
2024/09/23
学习Linux的最佳选择:五大理由支持红帽认证
2024/09/22
RHCE考试技巧分享
2024/09/21
HCIE认证过来人的实用学习攻略大揭秘
2024/09/20
最新华为HCIP认证报考详细内容
2024/09/14
2024年最新RHCE考试指南:时间_地点_内容与费用全解析
2024/09/14
一文带你了解OCM认证考试全攻略
2024/09/14
华为HCIA考试时间是什么时候?要考多久?
2024/09/12
oracle OCP认证与 MySQL OCP认证考哪个?
2024/09/09
华为HCIA、HCIP和HCIE认证:费用、难度与续证要求
2024/09/09
Oracle/MySQL OCP/OCM怎么备考?容易通过吗?
2024/09/08
甲骨文Oracle认证OCA/OCP/OCM有什么区别?
2024/09/08
2024年OCP认证备考指南:教材、培训与实践
2024/09/07
OCM认证考试有什么条件?
2024/09/06
华为HCIA认证报名指南:步骤、费用及注意事项
2024/09/05
如何获得HCIE-Datacom认证?
2024/09/04
红帽认证怎么考?RHCSA RHCE RHCA
2024/09/04
华为认证可以跳过HCIA,直接考HCIP吗?
2024/09/04
如何成为Linux红帽RHCA认证架构师?
2024/08/23
CISP认证培训与考试全攻略
2024/08/23
华为认证网络工程师有什么报考条件?如何高效备考?
2024/08/23
华为HCIE认证难考吗?
2024/08/12
华为HCIE是干什么的?华为HCIE证书难考吗?
2024/08/07
红帽RHCA怎么考
2024/07/31
就业新篇章|从迷茫到明确,CISP认证引领我开启无限可能的职业旅程
2024/07/27
华为认证实验考试深度解析与备考要点
2024/07/24
Python 有哪些特点?该怎么学习?
2024/07/23
华为云计算认证如何学?热门技能与就业前景全攻略
2024/07/12
CISP 认证是什么?有哪些就业机会?
2024/07/03
如何备考Redhat证书?实用技巧分享
2024/06/28
网络工程师必备书籍,建议收藏!!!
2023/11/01
特惠报名入口
验证码
提交
Oracle 索引怎么用?原理、分类及维护技巧
2025/10/07

索引是 Oracle 数据库中提升查询性能的核心工具,通过 “空间换时间” 的策略,减少数据检索时的 I/O 操作。本文将系统讲解 Oracle 索引的原理、分类、使用限制及维护技巧,帮助数据库管理员和开发人员合理设计索引,平衡查询效率与维护成本。
一、索引概述:用空间换时间的性能利器
二、索引的数据字典:查询索引元数据
1. 查看表的索引列表
2. 查看索引包含的列
三、限制索引使用的场景:并非所有查询都需要索引
四、Oracle 索引分类:按需选择合适类型
1. B 树索引:最常用的默认索引
2. 索引组织表(IOT):数据与索引合一
3. 唯一索引:保证列值唯一性
4. 反向键索引:解决索引叶节点争用
5. 降序索引:优化排序查询
6. 位图索引:适用于低基数列
7. 基于函数的索引:优化含函数的查询
五、索引维护:重建、合并与监控
1. 索引重建:彻底消除碎片
2. 索引合并:轻度碎片整理
3. 索引监控:识别无用索引
六、总结:索引使用的核心原则
-
开设课程 开班时间 在线报名OCP2025.04.26
在线报名
HCIP-AI Solution2025.04.26在线报名
HCIE-openEuler2025.05.03在线报名
RHCA-CL2602025.05.04在线报名
HCIP-Cloud2025.05.10在线报名
PGCM直通车2025.05.10在线报名
HCIA-Datacom(晚班)2025.05.19在线报名
HCIA-Sec2025.06.07在线报名
RHCA-RH4422025.06.07在线报名
PMP2025.06.10在线报名
HCIA-Datacom2025.06.14在线报名
HCIE-AI Solution2025.06.14在线报名
HCIE-Datacom2025.06.14在线报名
HCIP-Datacom(晚班)2025.06.16在线报名
OCM2025.06.21在线报名
HCIE-Cloud2025.06.21在线报名
HCIP-Sec2025.06.21在线报名
HCIE-Bigdata2025.06.28在线报名
RHCE2025.06.28在线报名
HCIE-Datacom考前辅导2025.07.05在线报名
HCIP-Datacom深圳2025.07.19在线报名
CISP2025.07.19在线报名
HCIA-Datacom(晚班)2025.07.21在线报名
RHCA-RH4362025.07.26在线报名
OCP2025.07.26在线报名
HCIE-Sec2025.08.09在线报名
HCIA-AI Solution2025.08.16在线报名
HCIP-Datacom(晚班)2025.08.25在线报名
RHCA-RH3582025.09.06在线报名
PMP2025.09.16在线报名
HCIE-Datacom2025.09.06在线报名
HCIA-AI Solution2025.09.27在线报名
HCIA-Datacom2025.09.27在线报名
PGCM直通车2025.10.11在线报名
RHCA-DO3742025.10.11在线报名
HCIA-Sec2025.10.11在线报名
RHCE2025.10.18在线报名
HCIP-Datacom2025.11.08在线报名
HCIP-Sec2025.11.08在线报名
RHCA-CL2602025.11.15在线报名
OCP2025.11.15在线报名
HCIE-Sec2025.12.13在线报名
HCIE-Datacom2026.01.10在线报名
在线精品
课程商城
人工智能训练师三级(高级工)
30课时

华为 HCIP-Datacom 考试服务
10课时

【直播课】华为HCIA-Datacom数通认证课程
36课时

华为云计算认证 HCIA HCIP-Cloud HCIE 培训课程
48课时