



























































































































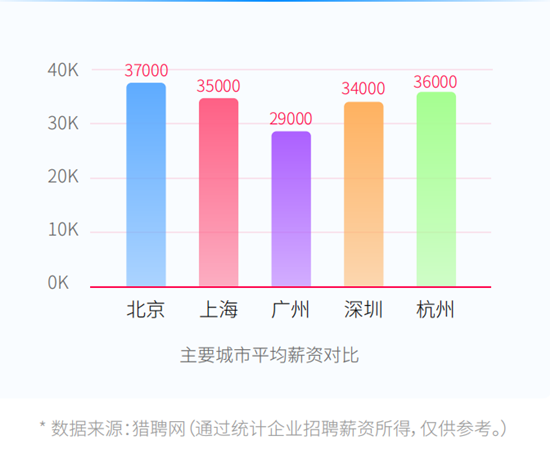




















































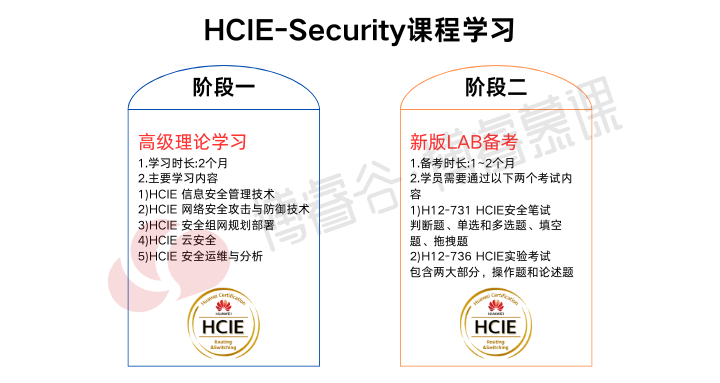










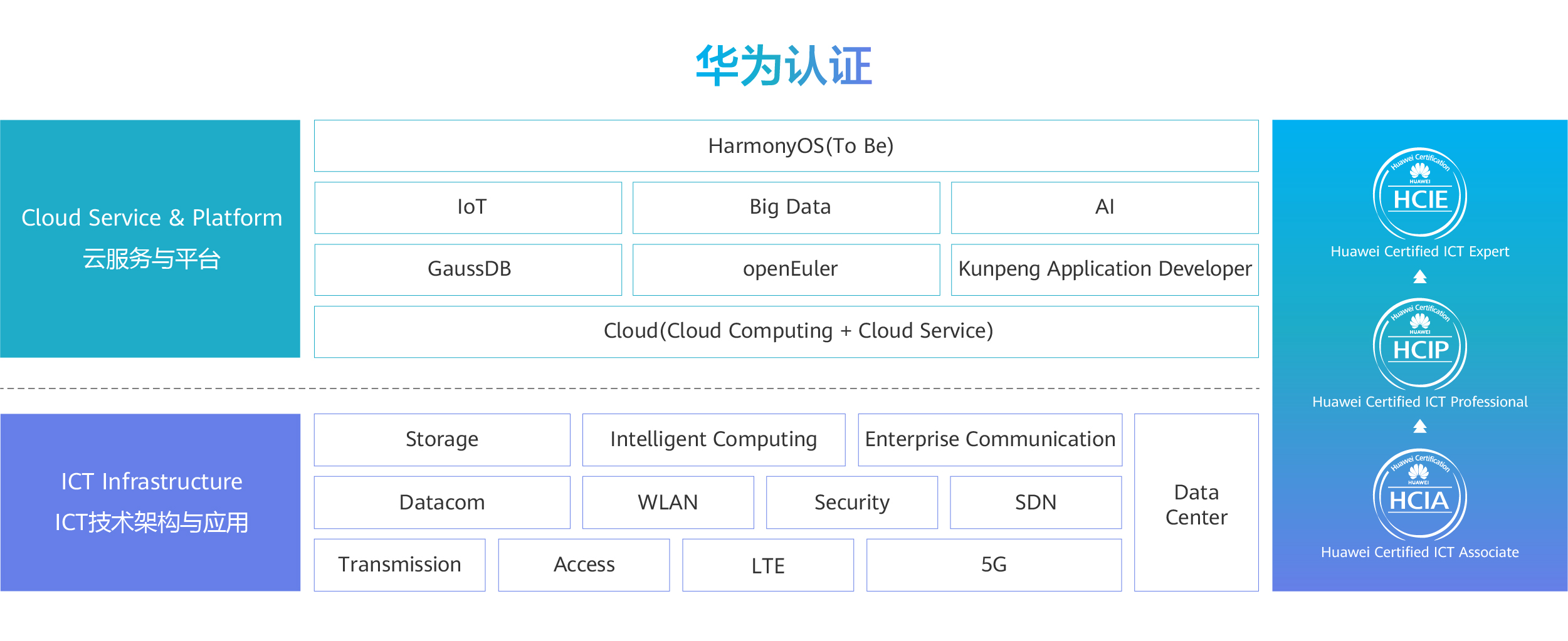




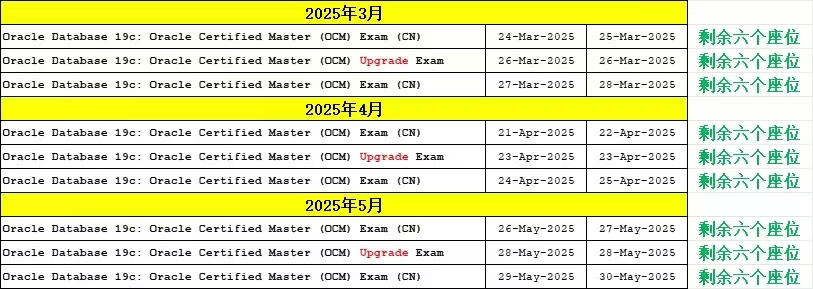
































































































































































2025下半年网工报名错过了吗?截止时间是?
2025/10/22
备考华为数通认证,实验环境怎么搭?步骤与坑点
2025/10/20
国内常用开源数据库有哪些?怎么选择?
2025/10/20
VMware 认证与其他 IT 认证相比,优势在哪?
2025/09/27
搞不清虚拟化架构和私有云架构的区别?看这篇就够了!
2025/09/25
2025 工信部 IT 证书怎么选?有补贴的证书及对应岗位推荐
2025/09/25
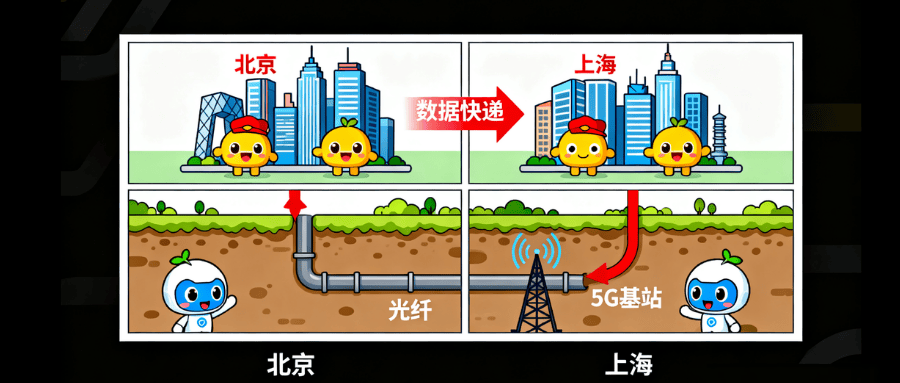
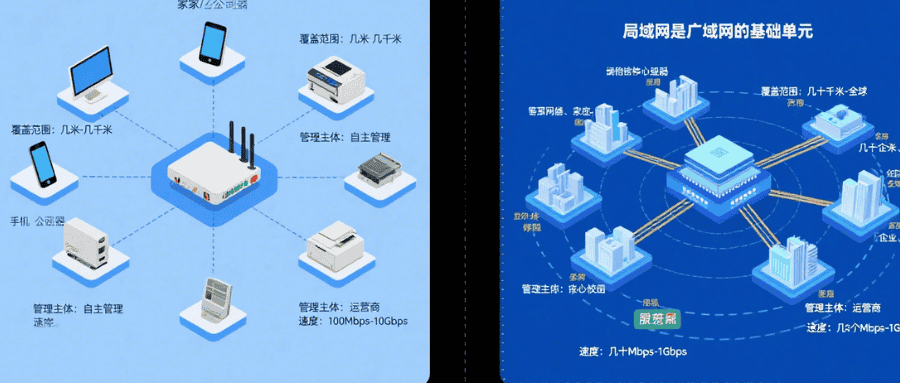
广域网(WAN)是什么?和局域网区别及日常应用有哪些?
2025/09/22
网络工程师职业发展 “寿命” 长吗?能长期干到退休吗?
2025/09/18
2025 年 DDoS 攻击防御指南,企业必看实用策略
2025/09/12
Linux 和 Windows 选哪个?核心差异看这些
2025/09/03
2025 年入行网络工程师:选思科认证还是华为认证?
2025/08/28
局域网和广域网的区别?
2025/08/28
华为 eNSP 有哪些替代工具?5 款主流网络仿真软件怎么选
2025/08/26
云计算工程师和网络工程师哪个适合你?
2025/08/25
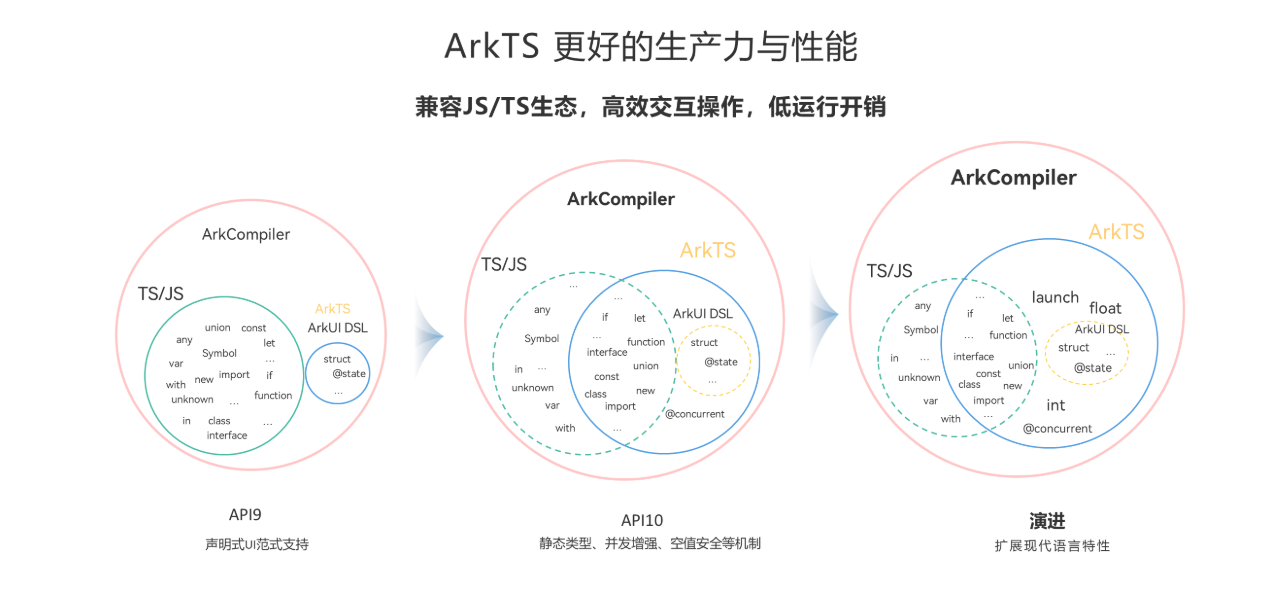
ArkTS 深度解析:HarmonyOS 应用开发核心编程语言特性与价值
2025/08/25
软考、PMP 还是信创?三者该如何选择?
2025/08/20
零基础转行学运维,考什么证书?
2025/08/11
软件开发哪些证书值得考?有你想要的吗?
2025/07/28
网络攻击有哪些防御策略?如何保护网络安全?
2025/07/21
华为lab考试考什么?和笔试有何区别?
2025/07/16
数据库常见问题及解决方法
2025/07/10
豆包智能体对话有隐私风险吗?
2025/07/08
HarmonyOS 分层架构设计优势是什么?
2025/07/03
想了解 AIGC 最新动态?这些要点不可错过!
2025/06/27
运维工程师推荐考的证书有哪些?
2025/06/26
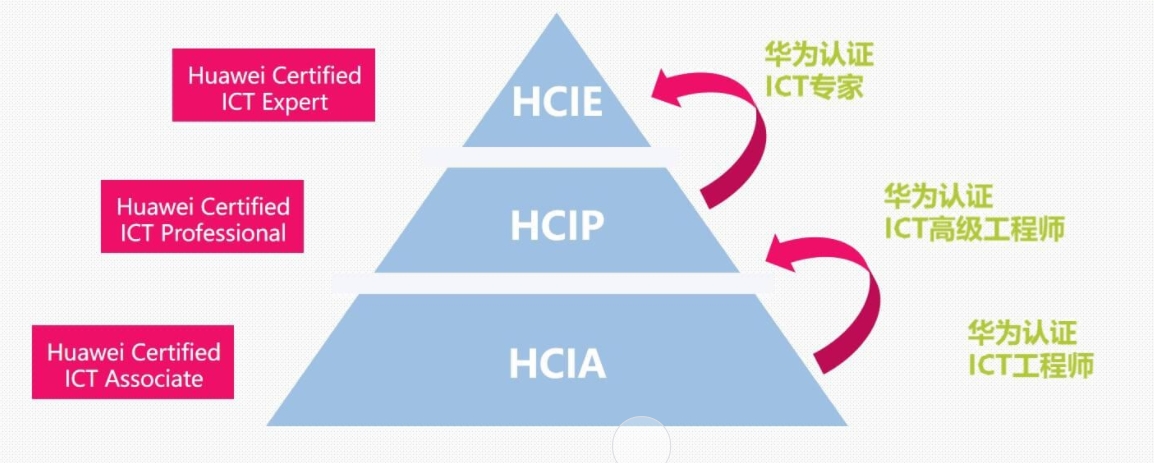
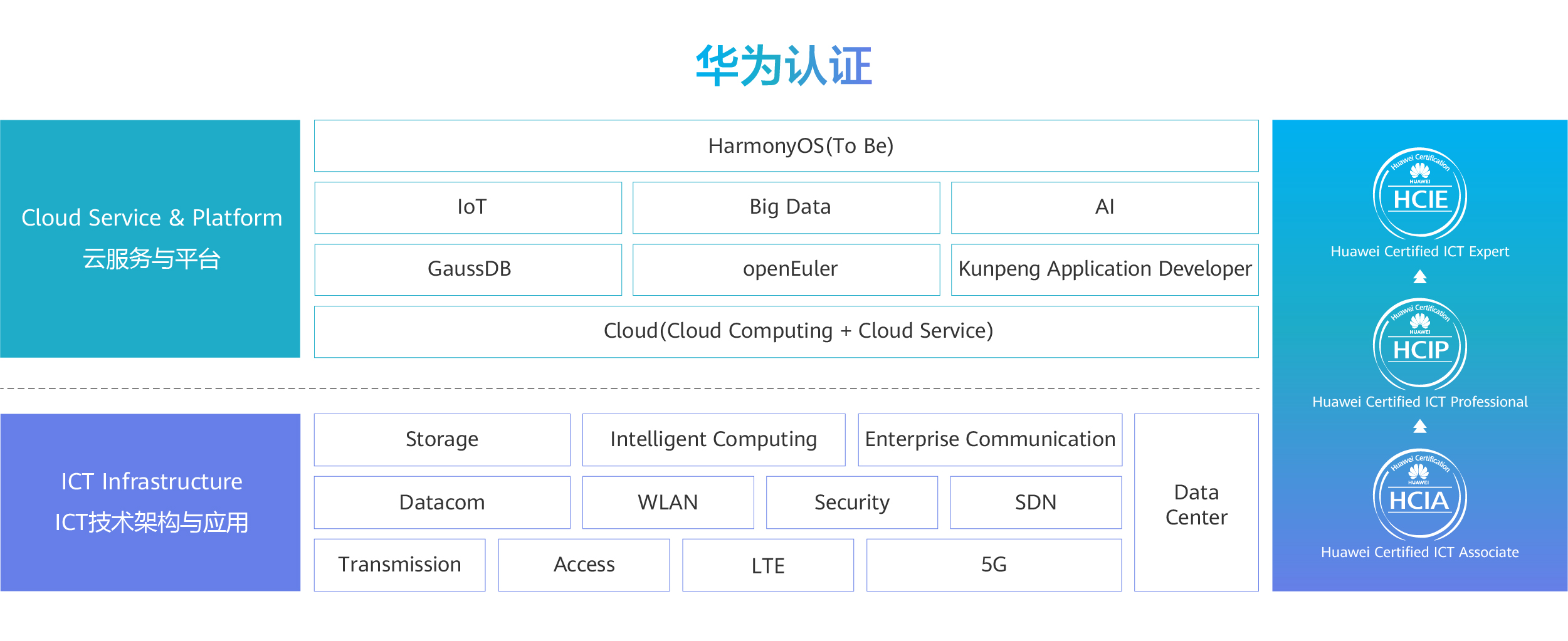
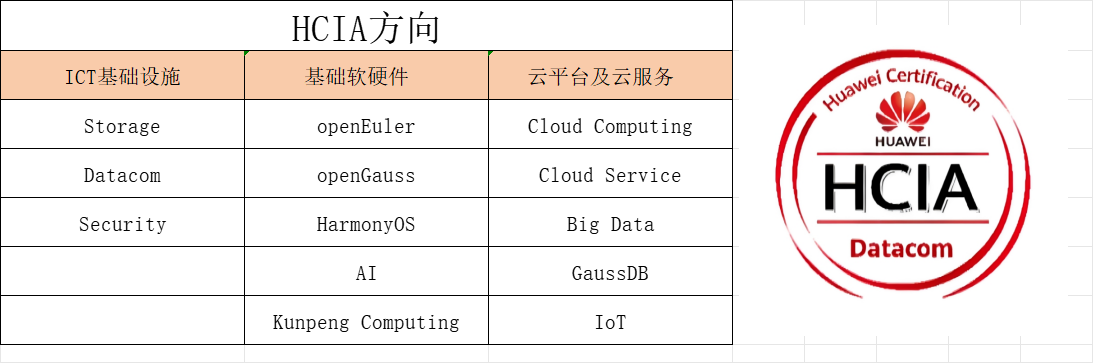
华为ICT到底是什么?
2025/06/19
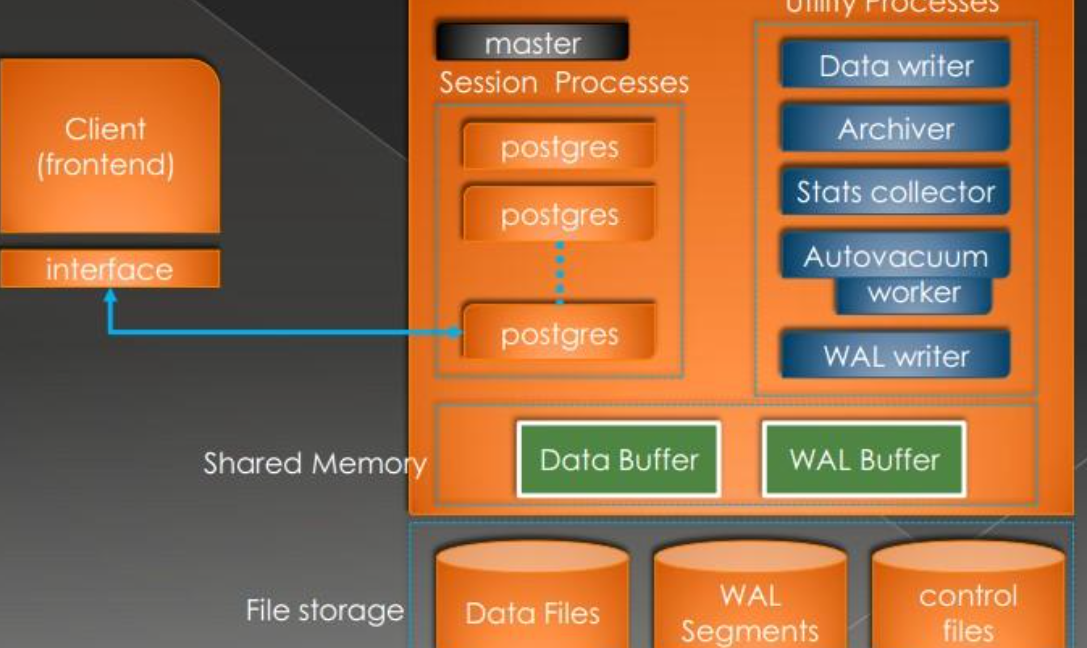
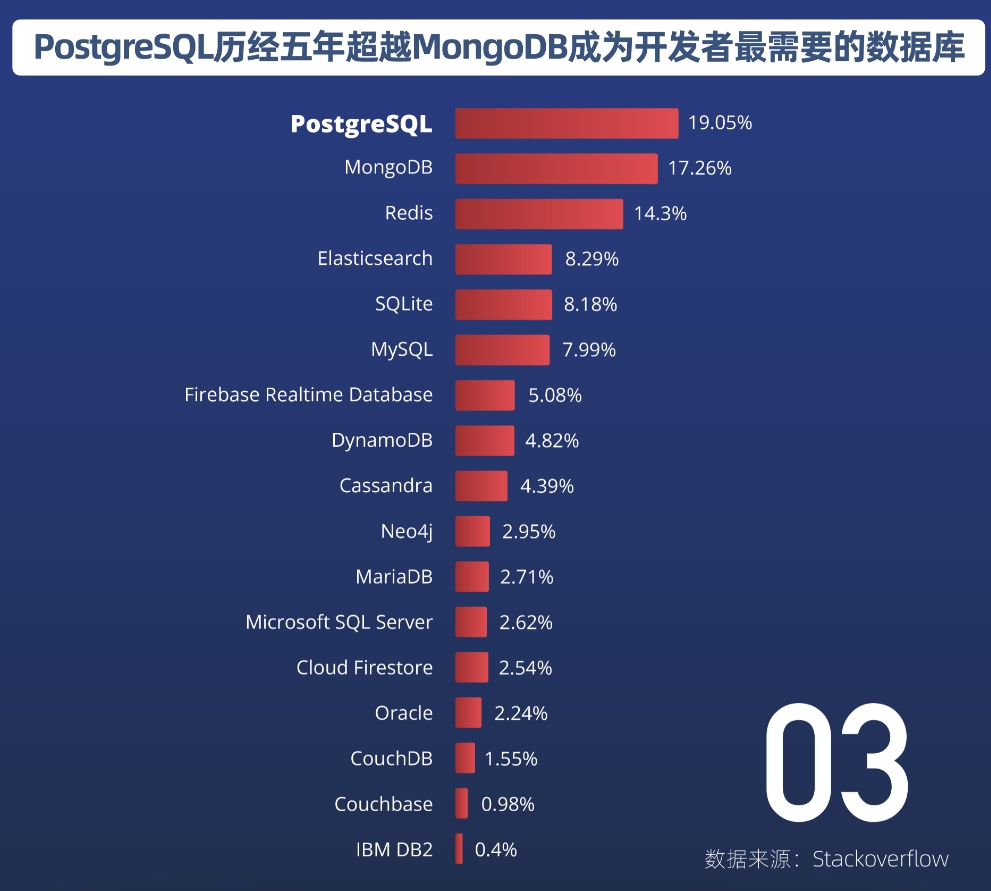
PostgreSQL数据库与Oracle数据库对比分析
2025/06/17
2025年6月华为HCIP-HarmonyOS认证将上线!值得考吗?
2025/06/12
OCM认证为啥这么难?全球通过率仅12%
2025/05/14
AI工程师高含金量证书有哪些?
2025/05/08
HCIE证书可以退税吗?哪些技术类证书符合条件?
2025/04/29
HCIE认证续期引争议:技术能力会"过期"吗?
2025/04/29
华为HCIE实验考试截图软件全新升级
2025/04/29
2025年物联网专业会火吗?全解析
2025/04/28
AIGC技术:值得深入了解吗?
2025/04/24
云计算HCIE认证值得考吗?2025年新增AIGC
2025/04/24
OpenStack是企业级云平台核心架构吗?
2025/04/22
VMware VCP认证考试全流程值得考吗?
2025/04/22
VMware VCP认证含金量高吗?
2025/04/22
零经验也能拿证?最新IT证书入门清单曝光
2025/04/17
云计算与大数据就业前景大比拼:哪个方向更值得投入?
2025/04/17
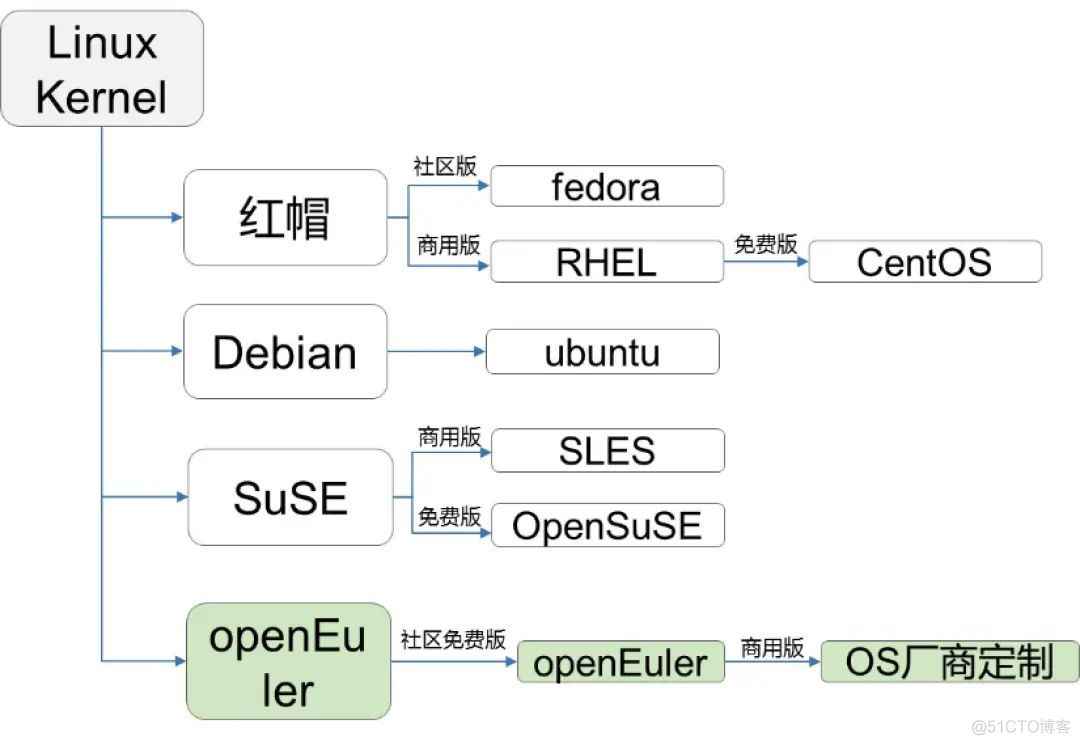
openEuler与其他操作系统有何区别?
2025/04/17
HCIE实验考试操作失误常见吗?如何避免配置完整性问题?
2025/04/11
华为HICE认证报名官网【入口】
2025/03/30
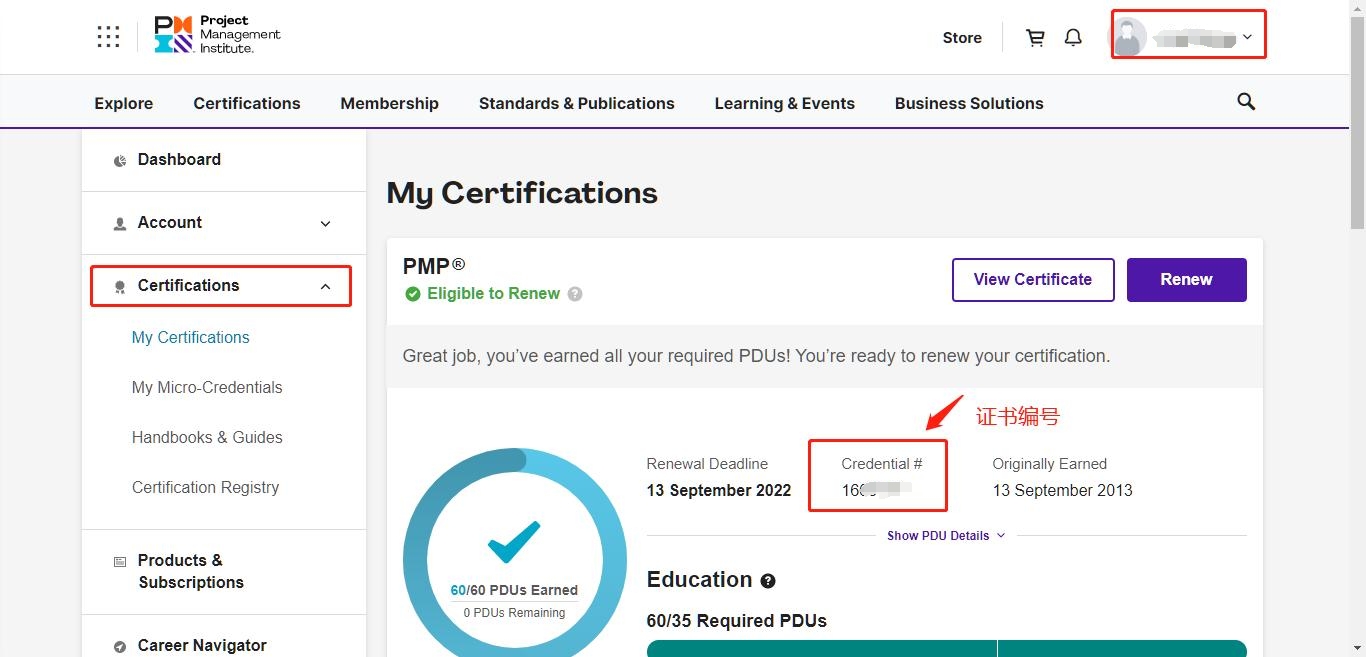
HCIE认证证书号重要吗?核心作用、风险防护与查询方法全解析
2025/03/27
红帽RHCE10.0认证有什么新变化吗?
2025/03/24
Linux认证价格调整了吗?最新价格是多少?
2025/03/20
信创数据库工程师(中级)全攻略
2025/03/12
考华为ICT认证能领2万补贴?人才补贴申请指南来啦!
2025/03/11
CKA认证考试如何一次通过?实战技巧全揭秘!
2025/03/10
华为“一试双证”值不值得考?技能补贴怎么领?
2025/03/09
华为认证AI工程师值得考吗?
2025/03/04
华为认证工程师职业发展报告:解密金牌证书与职场逆袭路径
2025/03/03
2024 IT打工人摸鱼指南!这些岗位正在偷偷涨薪!
2025/02/28
红帽认证考试最新的核心变化,你了解吗?
2025/02/26
任何利用RHCE技能处理访问升级?
2025/02/05
Apache HTTP Server虚拟主机配置指南
2025/01/23
华为HCIE是需要通过笔试才能报名实验考试吗?
2025/01/21
OCM认证需要考几门,考试费用是多少?
2025/01/20
RHCA含金量超级高,了解一下2025最新的考试费用
2025/01/20
HCIE的通过率怎么样?
2025/01/19
计算机专业华为考试是什么?有哪些方向可以选择?
2025/01/19
华为鸿蒙认证能带来的经济效益有哪些?
2025/01/19
OCP认证详细介绍,2025拿下OCP证书
2025/01/16
RHCA的含金量详细解说
2025/01/16
网络通信模型:OSI与TCP/IP的深度解析
2025/01/16
红帽RHCA认证中的OpenStack管理II(CL210)
2025/01/15
云计算主要是干什么的?有什么用?
2025/01/15
信创认证,今年的热门证书
2025/01/15
关于HCIP-Datacom证书,四招教你完成续期
2025/01/15
HCIP含金量怎么样?建议有条件还是去考一下
2025/01/14
Oracle OCP好考吗,通过的要求高不高
2025/01/14
一篇文章带你详细了解红帽认证
2025/01/14
数通为什么是小白的必学课程?
2025/01/14
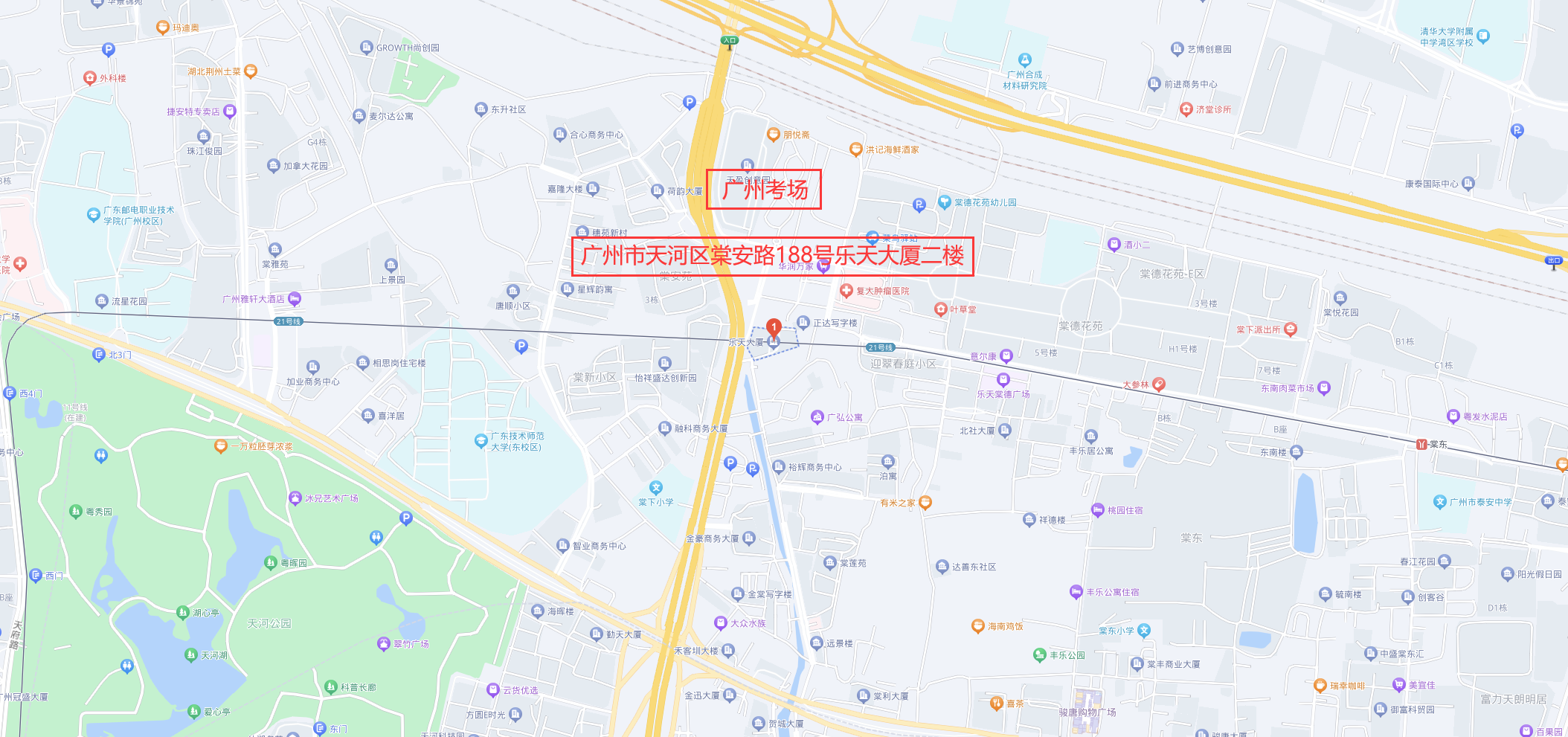
华为认证机构广州培训中心
2025/01/13
HCIE如何续认证,续认证的费用需要多少?
2025/01/13
RHCE考试,要如何报名?
2025/01/13
RHCE考试报名注意事项
2025/01/12
Oracle数据库DBA工程师职业介绍
2025/01/12
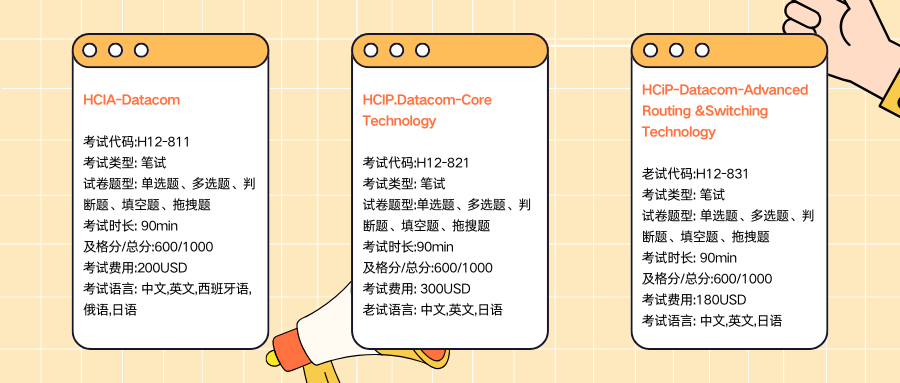
华为HCIA、HCIP、HCIE网络工程师费用解析
2025/01/12
红帽Linux培训机构哪家硬?
2025/01/09
RHCA认证中OpenShift容器平台管理和运维
2025/01/09
HCIP等级的云计算和云服务介绍
2025/01/09
RHCE红帽证书下载指南
2025/01/08
openEuler和主流OS系的关系
2025/01/08
HCIP认证的市场培训价格
2025/01/08
OCM最新考试时间和考试地点
2025/01/08
openEuler开课计划_广州博睿谷
2025/01/07
PGCE课程培训班_广州博睿谷
2025/01/07
RHCE需要学习哪些课程
2025/01/07
HCIP-openEuler的考试题型有哪些?
2025/01/07
OCM考证,大师认证培训班
2025/01/07
OCP认证指南:如何考、考什么内容、考了有什么用
2025/01/06
linux红帽运维认证介绍以及重认证
2025/01/06
HCIE网络工程师认证后的薪资高不高?
2025/01/06
openEuler华为认证考试预约流程
2025/01/06
AI崛起:程序猿的饭碗真的不保了吗?
2025/01/03
RHCA云计算认证详细介绍
2025/01/03
HCIE华为认证培训中心
2025/01/03
openEuler华为认证直通车班级
2025/01/02
hcnp培训费用详情
2025/01/02
RHCE红帽认证考试时间
2025/01/02
OCP考试有多少道题目?
2024/12/31
RHCE考试步骤,详细考试流程介绍
2024/12/31
数据库:PGCE,OCP,TIDB,哪个认证比较热门?
2024/12/28
华为ICT认证是什么?
2024/12/28
华为认证考试怎么报名?实验考试预约流程复杂吗?官方平台解答!
2024/12/28
RHCE实验环境需要都线下吗?
2024/12/27
HCIE-AI证书难度怎么样?
2024/12/27
鸿蒙认证应用开发知识点之类和接口
2024/12/27
2025年PMP考试最新报名通知
2024/12/27
华为认证网络工程师什么时候考?
2024/12/27
ITSS证书含金量介绍
2024/12/26
ITIL是什么证书?含金量怎么样?
2024/12/26
华为运维证书有哪些?
2024/12/25
RHCE考试时间安排及报名指南_广州博睿谷
2024/12/25
OCP-MySQL线上中文考试
2024/12/25
AI的简单介绍:智能科技改变生活方式
2024/12/24
红帽有哪些认证,培训需要多少钱?
2024/12/24
PMP项目管理热门证书之一
2024/12/24
Oracle OCP考试常见问题之线上考试流程
2024/12/24
华为欧拉开源操作系统认证,openEulerz证书
2024/12/22
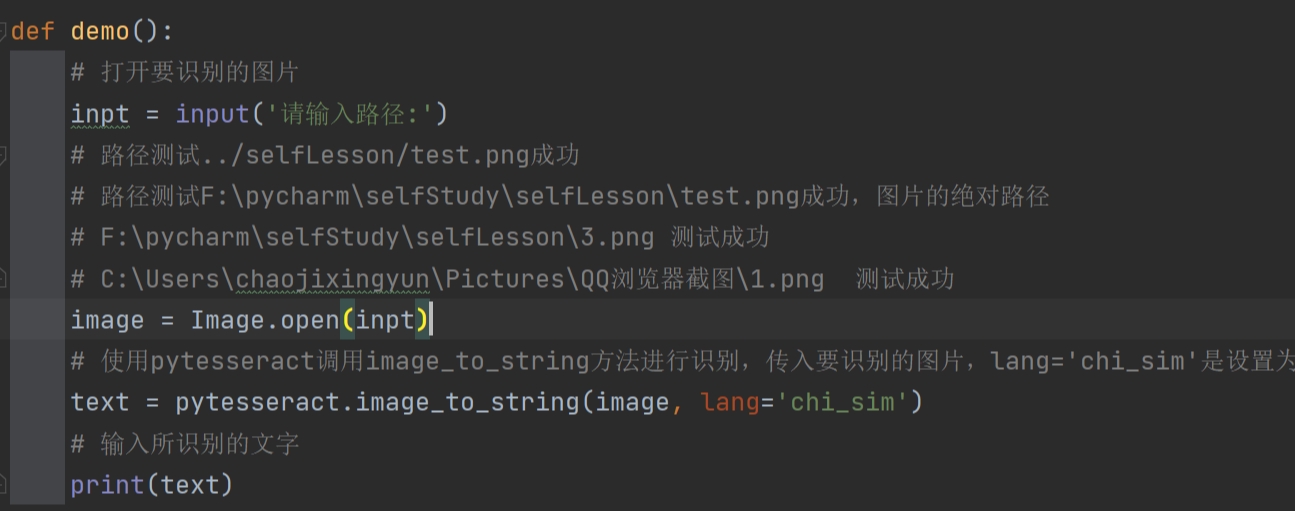
Python常用的开发工具有哪些?
2024/12/21
RHCA考了之后能做什么?
2024/12/21
Oracle数据库适合哪些人学?
2024/12/21
CISP报名考试费用需要多少?
2024/12/21
RHCE如何提升到RHCA_广州RHCA培训班
2024/12/20
HCIP认证后平均收入有多高?
2024/12/20
华为云计算可以往哪些职业方向发展,干货分享
2024/12/20
华为认证有哪些类别?
2024/12/19
华为云计算和红帽云计算,哪个好就业?
2024/12/19
OCP认证可以直接考吗?需要多少费用?
2024/12/19
Linux深度学习培训班
2024/12/18
HCIE通过率高吗?认证后薪资可以达到多少?
2024/12/18
RHCA和RHCE认证到底有多难?看完这篇文章你就明白了
2024/12/17
HCIA、HCIP、HCIE报名官网
2024/12/17
Oracle和MySQL在应用技术上有什么区别?
2024/12/17
红帽证书需要考哪几个证书?
2024/12/13
HCIP-openEuler 2024年的考试费用是多少?
2024/12/13
云计算的应用领域有哪些?发展前景如何?
2024/12/13
数据库管理员可以考哪些证书?
2024/12/12
RHCA红帽认证云计算架构师怎么考?
2024/12/12
云计算HCIE考试+培训一共需要多少费用?
2024/12/12
Oracle知识点:使用Oracle SQL实现自动增长字段
2024/12/11
PMP®在内地和香港考试有什么区别?含金量会不一样吗?
2024/12/11
博睿谷欧拉学习效果怎么样?openEuler的发展前景如何?
2024/12/11
OCM认证考点在哪里?北京上海广州考试安排全知道
2024/12/10
什么?华为认证HCIE实验考试全国只有5个考点?
2024/12/10
华为 HCIA 数通认证培训费用看这里,博睿谷帮您省钱
2024/12/09
华为HCIA-Datacom认证培训怎么安排?
2024/12/09
华为网络工程师证书有多火?看完涨知识了
2024/12/07
华为HCIE Lab考试报名渠道及备考策略
2024/12/06
从零开始学习OCP+OCM:一套高效学习方法分享
2024/12/06
PMP项目管理和CISP信息安全测评中心有关联吗
2024/12/06
RHCA云计算架构师学习资源
2024/12/05
华为安全网络工程师认证
2024/12/05
OpenEuler与红帽的运维系统有什么关联吗?
2024/12/05
高效记忆rhce命令的技巧
2024/12/04
华为HCIE安全网络认证的报考流程详解
2024/12/03
Oracle认证培训课程-ocp认证
2024/12/03
华为HCIE数通和安全的网络工程师哪个就业率高?
2024/12/03
Python网络工程运维
2024/12/02
RHCA云计算架构师培训班
2024/12/02
PMP项目管理的六大核心内容
2024/12/02
华为认证高级大数据 VS Oracle认证OCM
2024/11/30
openEuler操作系统官网全面解析:功能有哪些?如何下载安装?
2024/11/30
RHCA培训课程-CL210 openstack平台的管理
2024/11/30
RHCA-DO374培训课程 Ansible 自动化平台_博睿谷
2024/11/29
Oracle培训课程——ocm认证
2024/11/29
华为认证数通好还是安全好?哪个方向就业好?
2024/11/27
ocm认证的考试费用是多少?认证后薪资能达到多少?
2024/11/27
怎样获得rhca认证?报名条件及流程
2024/11/26
了解oca的重要性和申请流程
2024/11/26
hcna就是hcia,hcia证书的含金量解析
2024/11/26
RHCE和RHCA哪个含金量高?
2024/11/25
拥有OCM认证后可以在哪些岗位发展?_博睿带你了解详情
2024/11/25
高收入岗位:顶级网络安全工程师
2024/11/25
2024全新PMP指南_博睿带你了解PMP
2024/11/24
数通HCIE认证难度怎么样?通过率怎么样?
2024/11/24
RHCSA是合并到RHCE当中了吗?
2024/11/21
广州MySQL OCP报考流程
2024/11/21
MySQL在哪个行业需求较大?
2024/11/21
华为认证网络工程师可以往哪个方向发展?
2024/11/21
Oracle认证考试多少钱?在哪里报名?
2024/11/20
HCIA大数据考试难度怎么样?备考指南
2024/11/20
红帽RHCE认证培训报名官网
2024/11/19
如何提高大数据HCIP等级的通过率?实用复习技巧分享
2024/11/19
2024年HCIE-AI华为人工智能认证最新解析
2024/11/18
OCM数据库初学者必看:数据库OCM要怎么学?_培训订阅
2024/11/16
如何报名参加红帽认证培训?_博睿谷培训订阅
2024/11/16
HCIP-openEuler培训报名官网
2024/11/16
0基础学数通培训班推荐-广州博睿谷
2024/11/15
OCP证书需要考多长时间?费用是多少?
2024/11/15
红帽云计算培训课程_广州博睿谷
2024/11/15
RHCE考试没通过怎么办?抓住赠送的补考机会,复盘再战
2024/11/14
广州OCM认证中心_培训订阅
2024/11/14
HCIE-openEuler培训费用是多少?_广州培训班
2024/11/14
Oracle OCP认证培训课程:哪家培训机构性价比最高?
2024/11/14
HCIE-Security考试费用是多少?
2024/11/13
2024年新版HCIP-openEuler通过率高吗?
2024/11/13
广州IT教育培训机构推荐
2024/11/12
RHCE培训_精选培训机构介绍
2024/11/12
OCP认证培训课程_博睿谷·博睿慕课培训订阅
2024/11/12
HCIP培训认证官网_博睿谷培训订阅
2024/11/12
2024年网络工程师证书小白考证指南
2024/11/11
HCIE认证培训机构哪个好?博睿谷培训课程推荐
2024/11/10
HCIP认证哪家培训机构的口碑最好?博睿谷领先一步
2024/11/10
RHCSA认证考试指南:博睿谷全新订阅模式
2024/11/10
红帽认证考试常见问题解答
2024/11/10
刚毕业选择考华为认证值得吗
2024/11/09
HCIE和CCIE比较,哪个含金量高?
2024/11/09
顶端云计算架构师RHCA学什么?_博睿谷课程培训订阅
2024/11/08
HCIE笔试和实验可以同一天考完吗
2024/11/08
为什么我说华为证书在国内是万能证书
2024/11/08
看了这份备考攻略,你的OCM就稳了(附上2025年考试时间)
2024/11/08
打工人低成本学习openEuler,真的很香
2024/11/07
逆袭记:专科生在数据库领域的成长
2024/11/07
为什么建议运维工程师考个RHCE认证?
2024/11/07
华为认证HCIE-openEuler培训班需要多少钱?
2024/11/06
怎么查询华为认证证书?有效期是多久?延长证书的方法
2024/11/05
OCP考试时间预约注意事项_博睿谷·博睿慕课
2024/11/05
Python编程语言入门级课程
2024/11/04
PMP发票下载教程
2024/11/02
华为AI全光网助力运营商提升竞争力,开启新增长新时代
2024/11/02
华为HCIP认证最新变化:实验考试有了新要求?
2024/11/01
华为大数据和Oracle数据库有什么关联?
2024/10/31
华为HCIE-Security认证考下来多少钱?_博睿谷培训订阅
2024/10/31
2024年华为最新考试地点查看_博睿谷·博睿慕课
2024/10/30
2024年最新红帽RHCE考试地点有哪些?
2024/10/30
HCIP-Datacom认证有什么作用?
2024/10/30
哪种数据库认证更受老板青睐?_Oracle/MySQL
2024/10/30
华为欧拉HCIE-openEuler十天学习指南_博睿谷·博睿慕课
2024/10/29
2024年最新RHCE报名费用及考试时间_博睿谷培训订阅
2024/10/29
MySQL和Oracle的OCP考试的费用一样吗?
2024/10/29
有数通功底,转行网安困难吗?_过来人带你看看行情
2024/10/25
2024年热门证书:红帽云计算架构师_RHCA认证培训订阅
2024/10/25
Oracle OCM认证难度大吗?
2024/10/25
拥有ocp证书薪资可以达到多少?
2024/10/24
考前RHCE常见问题答疑
2024/10/24
cka认证和华为认证哪个更适合初学者?
2024/10/24
看完这篇文,轻松拿下HCIA证书
2024/10/24
除了华为,还有哪些公司认可华为认证?
2024/10/23
rhce工程师在企业中担任什么角色?
2024/10/23
MySQL和Oracle有什么区别?哪个更适合初创公司使用?
2024/10/23
一篇文章带你深入了解HCIP数通方向
2024/10/23
年薪50W的大数据工程师都是什么水平?
2024/10/22
全国数据库认证统一收费标准_ocp认证费用
2024/10/22
2024年红帽认证架构师RHCA考试注意事项
2024/10/22
openeuler操作系统是开源的吗
2024/10/22
RHCA-DO374课程难学吗
2024/10/21
华为认证数通方向有哪几科?
2024/10/21
Oracle OCM认证薪资待遇怎么样?
2024/10/21
OCA、OCP、OCM考试费用分别是多少?
2024/10/20
第九届华为ICT大赛中国编程赛_博睿谷订阅
2024/10/20
网络管理员需要会Linux吗?
2024/10/17
华为认证HCIP在找工作中有帮助吗?
2024/10/17
Sun Microsystems为什么会被Oracle公司收购?
2024/10/17
ITIL是什么证书?考了有什么作用?
2024/10/17
2024年华为认证Lab考试最新版考试指南_博睿谷培训订阅
2024/10/16
为什么程序员代码不能终身责任制?_博睿谷培训订阅
2024/10/16
网络安全大揭秘,选择华为还是思科?_博睿谷订阅
2024/10/16
华为Datacom和vmess之间有什么联系?_博睿谷培训订阅
2024/10/16
PMP考试一年可以参加几次?
2024/10/15
postgresql是国产数据库吗?
2024/10/15
广州OCM培训班_博睿谷·博睿慕课帮你找准方向
2024/10/14
2024年PMP项目管理考试备考资料分享
2024/10/14
HCIA-Cloud十月火热开课,抢先了解报名福利!
2024/10/13
哪些领域和公司特别重视RHCE认证的人才?
2024/10/13
博睿谷·博睿慕课助力鸿蒙原生应用开发者计划
2024/10/13
口算PK引发关注,编程大赛激烈升级_博睿谷培训订阅
2024/10/13
来搞懂华为HCIP云计算和HCIP云服务的区别?
2024/10/12
怎么选择华为认证培训机构?
2024/10/12
OCP数据库的报名价格_博睿谷·博睿慕课
2024/10/11
带你详细了解Python和C++在编程领域中的差异有哪些?
2024/10/10
全方位解析华为“一试双证”政策
2024/10/10
开源新篇章:OpenEuler操作系统
2024/10/09
最新!2024年华为HCIA考试报名攻略
2024/10/09
华为HCIA安全认证的毕业生就业率怎么样?
2024/10/09
PMP考试安排:2024年最后的备考机会
2024/10/08
大专生拥有HCIE证书年薪可以达到多少?
2024/10/08
Oracle与MySQL的语言有什么区别?
2024/10/08
华为认证笔试系统升级通知:考生须知
2024/10/07
大数据、云计算、物联网、区块链和人工智能 - 引领数字化转型的五大技术
2024/10/03
紧急页面访问升级:技术解决方案与预防措施
2024/09/30
openGauss数据库
2024/09/30
2024年PMP全面考试攻略
2024/09/30
数通hcie网络工程师考试费用详细说明
2024/09/30
红帽云计算RHCA认证班_广州博睿谷·博睿慕课
2024/09/28
广州HCIE认证考下来需要多少钱?
2024/09/28
华为初级工程师报名费用需要多少?
2024/09/27
华为HCIE-Datacom适不适合零基础考?
2024/09/27
华为认证大数据课程_博睿谷·博睿慕课
2024/09/27
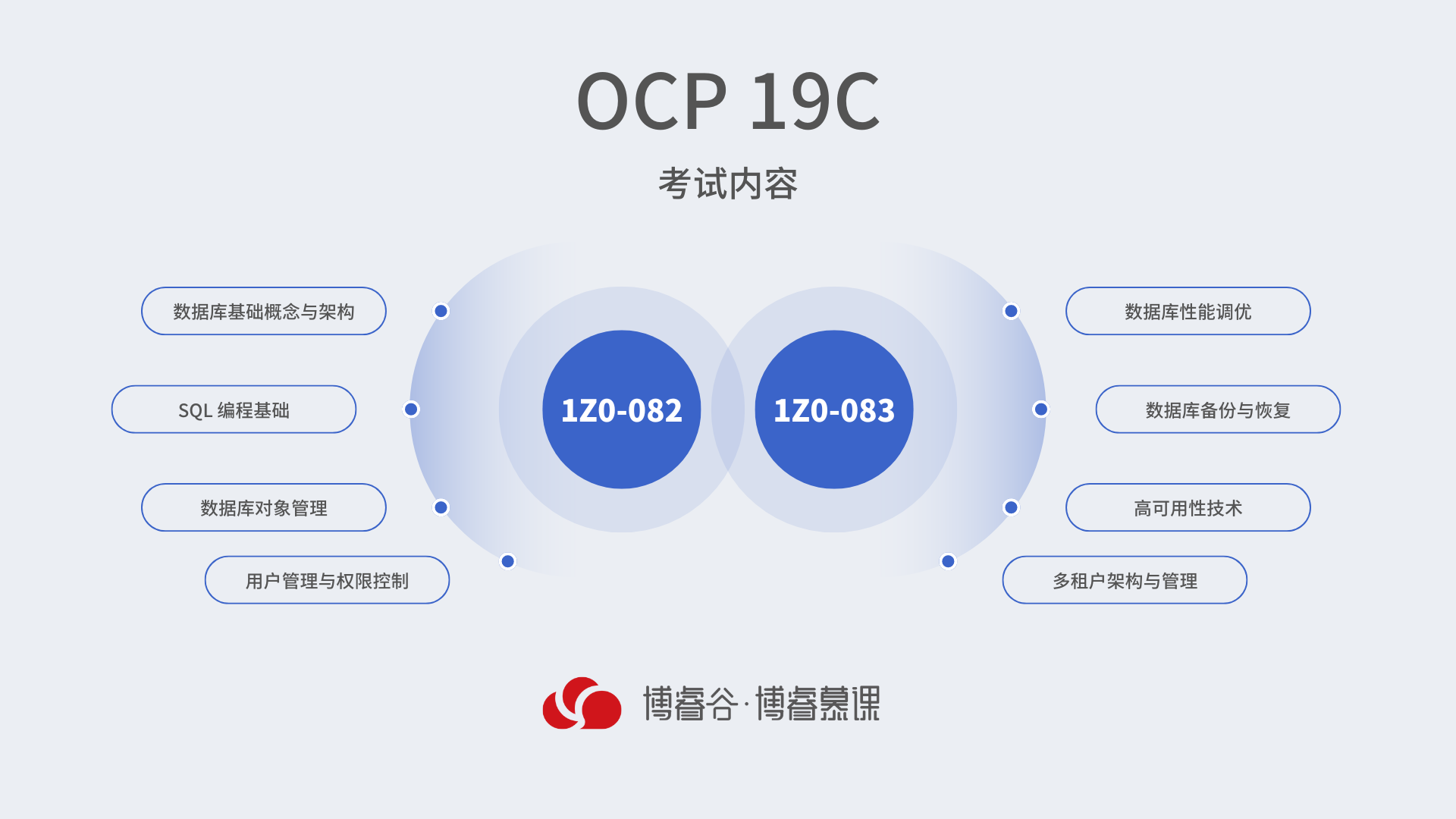
Oracle数据库专家_OCP 19C要考哪几门
2024/09/26
华为Security架构是怎么样的,学起来难吗?
2024/09/26
掌握hcie-datdaom就是打好了ICT多领域的基础
2024/09/26
RHCE认证报名费用及培训资源_博睿谷·博睿慕课
2024/09/26
PMP认证是项目管理的标准
2024/09/25
带你解读openEuler最新技术特性
2024/09/25
华为HCIE证书很难考吗?
2024/09/24
OCM证书还有什么作用吗?认证价值分析
2024/09/24
红帽认证报名费用_博睿谷IT培训
2024/09/24
博睿谷:您的IT认证培训伙伴
2024/09/22
HCIP证书对于刚毕业的学生有什么帮助吗?
2024/09/21
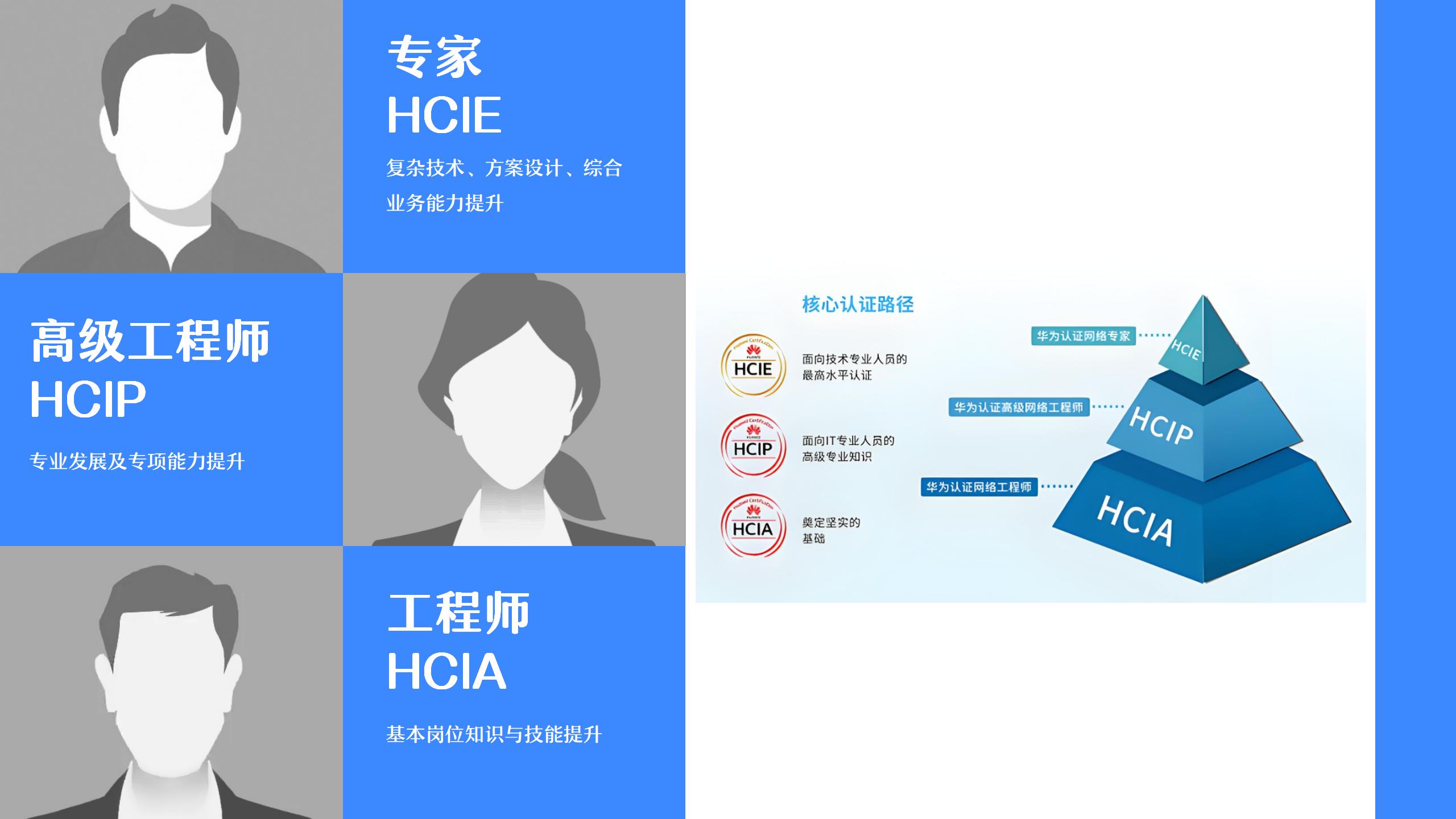
华为三个等级有什么区别,分别有什么作用?
2024/09/21
CISP证书还有必要考吗?是不是烂大街了?
2024/09/20
MySQL培训班_博睿谷·博睿慕课
2024/09/20
广东Linux认证培训班介绍_博睿谷培训
2024/09/20
Oracle OCP认证应该怎么准备考试?正确选择教材与培训课程
2024/09/19
RHCA培训课程材料,培训费用是多少?
2024/09/19
华为HCIE-Datacom证书工作好找吗?
2024/09/18
2024年下半年CISP认证培训课程费用介绍_博睿谷·博睿慕课
2024/09/18
华为安全认证:构建网络安全防线的最佳选择
2024/09/14
华为欧拉openEuler操作系统在企业级应用中有哪些优势和挑战?
2024/09/14
华为数通培训课程:从入门到精通
2024/09/13
2024年考RHCE还有用吗?
2024/09/13
2024年OCP认证证书的考试价格是怎么样的?
2024/09/13
RHCA和RHCE哪个更高级?
2024/09/11
oracle和mysql的区别
2024/09/10
华为HCIA认证报名官网与费用
2024/09/10
含金量高的证书有哪些?
2024/09/08
华为大数据工程师认证的含金量怎么样?难考吗?
2024/09/07
OCP含金量怎么样?值不值得考?
2024/09/07
广州RHCE培训班_博睿谷·博睿慕课
2024/09/07
199元学华为HCIA认证,轻松掌握零基础知识!
2024/09/06
博睿谷·博睿慕课:轻松实现IT技能提升的最佳选择
2024/09/06
CISP认证申请条件及费用详情
2024/09/05
关于RHCE报名流程和备考建议
2024/09/05
全面解析Oracle证书
2024/09/05
OCP考试费需要多少钱?
2024/09/04
OCM证书有什么作用?
2024/09/03
只需要2399元即可学习RHCE认证课程
2024/09/03
掌握Oracle数据库技能 | OCP认证基础培训课程
2024/09/02
红帽 Linux 运维工程师零基础培训课程
2024/09/02
华为HCIE认证通过率分析及提高技巧详解
2024/09/02
华为认证HCIA/HCIP/HCIE全套课程培训 | 博睿谷·博睿慕课在线学习
2024/09/02
Oracle认证培训的重要性
2024/08/30
2024年OCP的考试费用需要多少钱?
2024/08/30
2024年华为认证培训课程大约多少钱?HCIA HCIP HCIE
2024/08/30
Oracle培训机构有哪些?OCP OCM
2024/08/29
Oracle数据库的OCA OCP OCM培训费用分别是多少?
2024/08/28
红帽认证培训费用一览:RHCSA、RHCE与RHCA
2024/08/28
华为HCIE考试费用是多少?
2024/08/28
Oracle数据库OCM高级培训的含金量有多高?
2024/08/27
红帽RHCA认证培训课程有学什么内容?
2024/08/27
Oracle数据库专业课程培训内容
2024/08/26
HCIP认证含金量怎么样?考试流程是怎样的?
2024/08/23
华为HCIP数通题库资源
2024/08/22
红帽 RHCE 培训选哪家?博睿谷课程优势何在?
2024/08/22
OCP培训费用多少?考试费用是多少?
2024/08/21
华为HCIP培训机构推荐
2024/08/21
华为HCIE培训费用一般是多少?
2024/08/20
华为网络工程师认证全解析
2024/08/19
华为认证考试报名流程
2024/08/16
华为认证考试教材推荐与复习技巧
2024/08/16
红帽RHCE证书有效期是多久,过期了不续会怎样?
2024/08/09
华为HCIE培训机构该如何选择?选对培训班,事半功倍!
2024/08/05
鸿蒙系统开发培训班多少钱?
2024/08/02
揭秘华为认证openEuler:性能卓越、安全可靠的操作系统选择
2024/08/01
华为数通认证:数字通信领域的黄金标准
2024/08/01
华为认证考试费用
2024/07/30
华为认证培训费用是多少?
2024/07/30
PMP续认证流程全解析
2024/07/29
华为HCIP培训费特价来袭:1499元解锁高端技能新篇章
2024/07/26
2024年华为认证发布会圆满落幕:共筑数智未来,引领人才新篇章
2024/07/22
IT培训值不值得学?小白必看
2024/07/17
Java培训能让你月薪过万吗?
2024/07/16
AI时代哪些职业面临失业风险?新机会在哪里?
2024/07/15
Oracle认证值不值得考?数据库管理领域的权威认证全解析
2024/07/10
5G浪潮下的华为认证:加速您的ICT职业发展
2024/07/08
手机信息泄露如何防范?IT行业专家教你守护隐私
2024/07/06
IT行业的菜鸟奇幻升级之旅
2024/07/05
特惠报名入口
验证码
提交
K8s 集群总搭失败?多节点报错有解吗?附命令!
2025/10/17
黄老师

“按教程搭 K8s 集群,节点连不上;好不容易启动服务,多节点通信又报‘Timeout’;翻日志半天找不到问题?” 不少运维、开发新手都被这些报错卡过,其实 K8s 集群搭建涉及环境、网络、配置等环节,一点小疏漏就会翻车。今天针对 “集群搭建失败”“多节点报错”,拆解决策方案 + 实操命令,帮你少走弯路。
点击查看>>>深入解析 Kubernetes 架构组成,手把手完成 K8s 环境的安装、配置视频教学
一、先排查:K8s 集群搭建前的 3 个 “基础坑”
(一)环境配置得达标
(二)防火墙与 SELinux 要关掉
(三)容器运行时配置要对齐
二、多节点报错:3 类高频问题 + 命令级解决
(一)Master 初始化失败:“kubeadm init” 报错
(二)Worker 加不进集群:“kubeadm join” 报错
(三)节点通信异常:“kubectl get nodes” 显示 NotReady
三、避坑技巧:K8s 集群搭建的 3 个 “好习惯”
(一)用配置文件初始化,少踩参数坑
(二)报错先查日志,定位问题更快
(三)记录关键命令,后续维护方便

-
开设课程 开班时间 在线报名OCP2025.04.26
在线报名
HCIP-AI Solution2025.04.26在线报名
HCIE-openEuler2025.05.03在线报名
RHCA-CL2602025.05.04在线报名
HCIP-Cloud2025.05.10在线报名
PGCM直通车2025.05.10在线报名
HCIA-Datacom(晚班)2025.05.19在线报名
HCIA-Sec2025.06.07在线报名
RHCA-RH4422025.06.07在线报名
PMP2025.06.10在线报名
HCIA-Datacom2025.06.14在线报名
HCIE-AI Solution2025.06.14在线报名
HCIE-Datacom2025.06.14在线报名
HCIP-Datacom(晚班)2025.06.16在线报名
OCM2025.06.21在线报名
HCIE-Cloud2025.06.21在线报名
HCIP-Sec2025.06.21在线报名
HCIE-Bigdata2025.06.28在线报名
RHCE2025.06.28在线报名
HCIE-Datacom考前辅导2025.07.05在线报名
HCIP-Datacom深圳2025.07.19在线报名
CISP2025.07.19在线报名
HCIA-Datacom(晚班)2025.07.21在线报名
RHCA-RH4362025.07.26在线报名
OCP2025.07.26在线报名
HCIE-Sec2025.08.09在线报名
HCIA-AI Solution2025.08.16在线报名
HCIP-Datacom(晚班)2025.08.25在线报名
RHCA-RH3582025.09.06在线报名
PMP2025.09.16在线报名
HCIE-Datacom2025.09.06在线报名
HCIA-AI Solution2025.09.27在线报名
HCIA-Datacom2025.09.27在线报名
PGCM直通车2025.10.11在线报名
RHCA-DO3742025.10.11在线报名
HCIA-Sec2025.10.11在线报名
RHCE2025.10.18在线报名
HCIP-Datacom2025.11.08在线报名
HCIP-Sec2025.11.08在线报名
RHCA-CL2602025.11.15在线报名
OCP2025.11.15在线报名
HCIE-Sec2025.12.13在线报名
HCIE-Datacom2026.01.10在线报名
在线精品
课程商城

华为HCIE-AI Solution认证课程 | 人工智能培训
60课时

华为云计算全栈认证直通车 Cloud Computing HCIA-HCIP-HCIE
168课时

华为认证安全Security HCIA-HCIP-HCIE(直通车)
264课时

华为数通认证HCIA-HCIP-HCIE直通车|Datacom网络工程师培训
258课时